백엔드 엔지니어 김대현
소개
안녕하세요. 백엔드 개발자 김대현입니다! 👋
이제까지, 카카오(다음), NHN, 라인플러스에서 일했고, 현재는 컨스택츠라는 작은 스타트업에서 Haskell이라는 함수형 프로그래밍 언어로 백엔드 시스템을 구축하고 있습니다.
제주도🏝 바닷가에서 한적하게 쉬며 커피☕️ 마시는 것을 좋아합니다.
Medium에 개발 관련한 글을 적기도 하고, YouTube에도 개발 관련 영상을 올리고 있어요.
제 관심 분야를 적으면, 앞으로 공유할 글들에 대한 방향성을 가늠하시기 좋을 것 같습니다.
함수형 프로그래밍
제 관심 분야 중 가장 먼저 꼽고 싶은 것은, 함수형 프로그래밍입니다. 현재 대부분의 주요 프로그래밍 언어는 "명령형 프로그래밍" 스타일입니다만, 함수형 프로그래밍의 장점들이 꽤 녹아들고 있는 것 같습니다.
함수형 프로그래밍 언어 | (1) Clojure
'해커와 화가'라는 책을 읽고, LISP라는 함수형 프로그래밍 언어에 관심을 갖게 되었습니다. 그러다 JVM이 널리 쓰이는 현업 환경에서 쓰기 좋은 클로저(Clojure)를 접하게 되었고, 그 매력적이고 강력한 언어에 빠져들었습니다. 이제껏 배운 언어 중, 리스프 계열 언어들이 가장 우아하다 생각합니다만, 현업 환경의 다수의 개발자들에게 리스프의 모양새는 꽤나 (충격적)이기 때문에, 규모 있는 회사에서 적용해 쓰기에는 부담이 있어 아쉬웠지요.
(defroutes 라우터
(GET "/" [] 핸들러)
(POST "/echo-name" [name]
(str "안녕하세요, " name "님!"))
(GET "/index.html" _
(html [:main
[:section
[:h1 "안녕하세요"]
[:div "클로저 웹서비스 데모"]]]))
(route/not-found "찾을 수 없습니다"))
(clojure + compojure)를 이용해 HTTP 서비스를 구성한 예제입니다. 리스프 계통 언어에 익숙하신 분들에게는 아주 자연스러운 코드일 텐데요, 대부분의 개발자들은, 다른 언어에서보다 많아 보이는 괄호 쌍()으로 인해 거부감을 느끼는 것 같습니다. 익숙해지면, 저 간결한 괄호식들이 참 우아해 보인다는 걸, 믿으실지 모르겠습니다.
함수형 프로그래밍 언어 | (2) Scala
그러다가, LINE 광고개발본부에 입사했는데, 이미 본부 내 몇몇 팀에서 스파크(Spark)를 이용하며 스칼라(Scala) 코드베이스로 개발을 하고 있었습니다. 이에 용기를 얻어, 제가 진행하게 된 신규 프로젝트를 스칼라로 하겠다 보고드렸고, 공식적으로 스칼라 함수형 프로그래밍으로 현업 서비스를 개발해 일본과 대만에 오픈했습니다.
게다가 스칼라로 함수형 프로그래밍을 하려는 개발자 분들이 여럿 저희 팀에 합류해 주셔서, 별다른 외압(?) 없이 스칼라 함수형 프로그래밍을 잘할 수 있게 되어 감사했습니다. 아무리 함수형 프로그래밍이 좋다한들, 충원이 되지 않으면 무슨 소용이 있겠습니까?
trait Semigroup[A] {
def combine(x: A, y: A): A
}
trait Monoid[A] extends Semigroup[A] {
def empty: A
}
implicit val intAdditionMonoid: Monoid[Int] = new Monoid[Int] {
def empty: Int = 0
def combine(x: Int, y: Int): Int = x + y
}
def combineAll[A: Monoid](as: List[A]): A =
as.foldLeft(Monoid[A].empty)(Monoid[A].combine)
combineAll(List(1, 2, 3)) // res3: Int = 6
스칼라 코드의 모양을 소개하기 위해, Cats라는 라이브러리의 Monoid 설명서에 나와있는 예제를 가져와봤습니다. 그래도 스칼라는, 일반적인 명령형 프로그래밍 언어와 겉모습이 비슷하기에, 그리고 스파크라는 프레임워크 덕분에, 업무 환경에 도입해 쓰기에 부담이 적은 것 같습니다.
라인개발실록 인터뷰
당시 저희 팀에서 함수형 프로그래밍을 하고 있단 소식에, 인터뷰까지 진행하게 되었습니다. 진행자 민우님이 잘 이끌어 주셔서 (제게는) 재미있는 영상이 남았습니다. 언젠가 좀 더 본격적으로 함수형 프로그래밍을 소개하는 영상을 남기고 싶네요.
함수형 프로그래밍 언어 | (3) Haskell
클로저와 스칼라는 함수형 프로그래밍 언어로 분류할 수 있습니다. 한편, 함수형 프로그래밍의 끝판에는 "순수" 함수형 프로그래밍 언어인 하스켈(haskell)이 있습니다. 어떻게 제게 이런 행운이 흘러드는지, 하스켈마저도 업무용으로 쓸 수 있게 되었습니다.
2022년 소개를 적는 현재, 컨스택츠라는 스타트업에서 신규 백엔드 시스템을 하스켈로 구축하고 있습니다. 아마도 국내에서 유일하게 하스켈을 실무에 활용하는 회사가 아닐까 합니다. 그래서 저희는, 농담 섞어서, 국내 하스켈 개발자 Top 10 중 3명이 근무 중인 회사라고 허세를 부리고 다닙니다. 국내에 실무 하스켈 개발자가 열 명이 안될 거라는 매우 합리적인 추측 때문에 가능한 농담이죠.
quickSort :: Ord a => [a] -> [a]
quickSort [] = []
quickSort (x:xs) =
quickSort smaller ++ [x] ++ quickSort larger
where
(smaller, larger) = partition (<= x) xs
--- >>> take 11 $ quickSort [1..30000000]
-- [1,2,3,4,5,6,7,8,9,10]
퀵소트 알고리즘을 구현한 하스켈 코드를 가져와봤습니다. 첫줄에 타입 선언이 있고, 이어서, 빈 리스트와 그렇지 않은 리스트에 대한 함수 본문이 나와있습니다. 퀵소트는 주어진 리스트에서 피벗 요소를 기준으로 작은 요소들과 큰 요소들의 리스트로 나눠서 재귀(recursion)로 구현할 수 있는데요, 지금 말로 설명한 부분이, 코드에 그대로 직관적으로 반영되어 멋진 것 같습니다.
하스켈은 엄격한 정적 타입 시스템을 갖춘 순수 함수형 프로그래밍 언어입니다. 순수 함수형 언어는, 함수 내에서 부수효과를 일으킬 수 없기에, 무언가 효과를 일으키기 위해서는 효과자체를 문맥에 담아 표현하고, 그 문맥을 다루기 편하게 하기 위해, 수학적 이론을 바탕으로 한 모나드(Monad)를 적극 활용합니다.
하스켈에 대해서도 차차 소개할 수 있게되기를 기대해봅니다.
사이드 프로젝트
다음으로 꼽을만한 관심 분야는, 때때로 진행하는 사이드 프로젝트입니다. 결과물이 공개적으로 잘 드러나는 프로젝트를 하려고, 프론트엔드 개발도 기웃거릴 때가 있습니다. 아무래도 본업은 백엔드 개발자이기 때문에, 프론트엔드 개발자 분들이 보시기에는, 어설픈 작업물일 가능성이 높습니다만, 그래도 재밌게 개발하고 있습니다. 틈틈히 연습해두니까, 백엔드 개발자로서, 간혹 필요한 웹화면을 만들기에 좋습니다. 구축한 시스템의 웹 관리 페이지를 만들 때도 유용합니다.
프론트엔드 프로그래밍 | (1) Elm
프론트엔드 개발에 좋은, Elm이라는 함수형 프로그래밍 언어가 있습니다. 하스켈과 마찬가지로 순수 함수형 프로그래밍 언어이고, 언어 기능이 간략해서 배우기 쉽고, 웹에 특화돼 있어서, 곧바로 웹 개발을 하기에 좋습니다. 아쉽게도, 쓰는 사람이 많지는 않기 때문에, 학습 자료를 찾아보기에는 아쉬운 점이 많은 것 같습니다.
update : Msg -> Model -> ( Model, Cmd Msg )
update msg model =
case msg of
LinkClicked urlRequest ->
case urlRequest of
Browser.Internal url ->
( model, Nav.pushUrl model.key (Url.toString url) )
Browser.External href ->
( model, Nav.load href )
UrlChanged url ->
( { model | url = url, route = urlToRoute url }, Cmd.none )
UpdateProjectFilter f ->
( { model | projectFilter = f }, Cmd.none )
제 개인 홈에 이용한 Elm코드의 일부를 가져와 보았습니다. 하스켈과 비슷하게 타입 선언을 먼저 두고, 커링도 활용하며, 패턴 매칭으로 메시지를 받아서 처리하는 코드입니다. 저같은 아마츄어가 프론트엔드 개발을 하려할 때, 꽤 든든한 힘을 입어 개발할 수 있어서 좋은데요, 다른 분들의 관심은 적은 언어라는 아쉬움이 있네요. 개인 단독 프로젝트를 진행할 때 이따금 사용할 것 같습니다.
프론트엔드 프로그래밍 | (2) TypeScript
아마도, 제가 프론트엔드 개발을 조금 더 기웃거린다면, 타입스크립트(TypeScript)를 많이 활용할 것 같습니다. 이제 정적 타입 언어가 더 친숙해지기도 했고, 타입스크립트를 활용하는 사람은, 제가 사용하는 마이너 언어들에 비해 대단히 많기 때문에, 많은 분들과 소통하기에는 타입스크립트가 가장 적절하지 않나 생각하고 있습니다.
function reorderFace(from: (n: number) => number): FaceFunc {
return (face: Face) => {
const target = face.slice()
face.forEach((x, n) => target[from(n)] = x)
return target
}
}
const clockwiseF = (x: number) => (7 * x + 6) % 10
const counterclockwiseF = (x: number) => (3 * x + 2) % 10
const halfTurnF = (x: number) => 8 - x
const clockwise = reorderFace(clockwiseF)
const counterclockwise = reorderFace(counterclockwiseF)
const halfTurn = reorderFace(halfTurnF)
최근 작업 중인, 사이드 프로젝트의 코드 일부를 가져와 보았습니다. 자바스크립트(JavaScript)와 거의 같은데, 중간중간 타입을 선언하는 점이 큰 차이점입니다. 제가 쓰는 글에서 코드로 무언가를 설명해야 할 때, 타입스크립트를 주로 써봐야겠다고 생각하고 있습니다. 참고로, 방금 언급한 사이드 프로젝트는 아래 주소에서 확인 가능합니다.
반갑습니다
이상, 함수형 프로그래밍과 사이드 프로젝트라는 두가지 관심사를 말씀드리면서, 장황한 소개를 적어보았습니다. 글로나마 다른 개발자분들과 서로 좋은 긍정적 힘 주고받으며 지내면 좋겠습니다.언젠가 오프라인에서 만나면 더 반가울 것 같습니다.
2022년 7월 18일 작성
행복한 개발자가 되는 길 (2) — I may be wrong
지난 글에 호응이 과분하여, 더 용기를 내어 같은 주제의 글을 쓰기로 했습니다. 마침, 지난 글을 올린 즈음에, 가까운 주변 개발자 한 분의 하소연을 듣게 되었는데, 그 불편한 심리 상태의 원인이 꽤 공통적이라는 점에서 다음 주제가 바로 떠올랐어요. 불편한 심리 상태에 빠져있는 당장의 상황에서는 이런 의견을 드려도 들리지 않기 때문에 바로 전달드리기는 어려웠습니다. 아니, 사실 이런 의견은 누구도 듣기 싫어할 것 같습니다. 이렇게 글로 적어뒀는데, 무심히 읽게 되어 공감이 드는 부분이 있다면 다행인 정도이겠습니다.
내가 맞다는 환상
어쩌면 본능의 영역인 거 같기도 하고, 아니면 학창 시절 시험 문제에 정답을 적어내야 하는 교육 과정에 따른 악습인 것 같기도 합니다. 어떤 원인인지는 모르겠지만, 우리 대부분은 "내가 맞다"라는 환상에 사로잡혀 있는 것 같습니다. 때로는, 내가 틀린 걸 쿨하게 인정하고 넘어가기도 하지만, 이건 미처 내가 관심 갖지 않았던 무지한 영역에서일 뿐이고, 잘 안다고 생각하는 자신 있는 부분에서는 틀린 걸 인정할 수 없습니다. 틀린 걸 인정하지 못하는 것은 물론이고, 남이 조금이라도 틀린 표현을 하면 바로 지적을 해서 바로잡아주고 싶어 하지요. 내가 자신 있는 부분인데 날 틀렸다고 지적한다? 그럼 맞서 싸워서 내가 맞고 남이 틀리다는 걸 인정하게끔 하려고 합니다. 생판 모르는 사람과도 말이죠.
시험을 볼 때나, 일을 할 때나 어떤 중요한 부분에 있어서는 이런 자세가 중요할지도 모르겠습니다. 하지만, 나머지 일상 대부분에서는 이 맞고 틀리고가 그다지 중요하지 않습니다. 이것도 맞고 저것도 맞을 수도 있고, 취향의 차이일 뿐, 맞고 틀리고의 문제가 아닌 경우도 많습니다.
"내가 맞다"는 환상은, "남이 틀리다"라는 환상으로 이어지고, 반대로 "남이 맞다"면 "내가 틀리는" 고통으로 이어지기도 하는데요, 왜 굳이 내가 꼭 맞아야 합니까? 틀린 지식을 갖고 있으면 죽어나가는 생존의 문제에 놓여있기라도 한 것처럼요.
내가 틀릴 수도 있습니다

겸손한 마음으로 "내가 틀릴 수도 있다"라고 표현하는 수준을 뛰어 넘어서, "틀려도 된다"라는 용기를 내야 합니다. 내가 틀릴 수도 있다는 가능성을 열어두면, 다른 의견에 대해 열리고 배우기 편해지고, 마음이 불편한 지점도 대폭 사라지며, 싸울 일도 줄어듭니다.
내가 틀려도 된다면, 상대 역시 틀려도 되며, 설령 상대가 명백히 틀리다고 할지라도 인정할 수 있습니다. 나에게도 관대하고, 타인에게도 관대해지면 되는 거죠. 틀린 걸 알게 됐을 때, 겸허히 배우면 됩니다. 굳이 정정할 필요가 없다면 안 해도 됩니다. 틀려도 되는 거니까요.
"틀려도 된다"라는 생각에서 큰 해방감이 이어집니다. 개발자가 뭐 평생 시험을 보는 상태에 있는 건 아니잖아요. 물론 때로는 맞고 틀리는 문제가 상당히 중요한 걸 무시하자는 게 아닙니다. 그렇지 않은 영역에서 쓸데없는 고민을 부릴 필요가 없다는 점을 말씀드리는 거예요.
지금, 제 의견이 어떤 점에서 틀렸는지를 지적하고 싶으신가요? 이미 그것이 "당신이 맞고", "제가 틀리기" 때문에 그런 생각이 드는 겁니다. 이미 "내게 맞는 의견이 있는데, 저 사람이 날 틀렸다고 말하네?"라는 흐름인 겁니다.
전 지금 제 글의 내용이 틀려도 되고, 당신의 내용이 맞다고 생각합니다. 이 자체로 너무 편안해요.
각자의 세상에서
우리 모두 한 세상에서 살고 있지만, 다 나름의 관점에서 세상을 바라봅니다. 사실상 각자의 세계가 너무 다른 상태인 거죠. 이 세상과 세상이 만나서 얘기하다 보면, 세계관이 달라서 빚어지는 충돌들이 있습니다. 긍정적 충돌일 때도 있고 소모적인 부정적 충돌일 때도 있습니다.
각자 내 세계와 그들의 세계가 다름을 인정하고, 서로의 세계를 일치시키려는 불필요한 시도를 포기할 때에 엄청난 에너지가 절약되는 것 같습니다.
모두가 사랑으로 하나의 세상
위대한 스승들은 이 세상이 사랑으로 가득 찬 하나의 세상이라고 하더군요. 언젠가 깨닫게 된다면 그런 통합의 세상에 눈을 뜰지도 모르겠지만, 아직 현실 세계에서 그저 조금 마음 편한 자세를 유지하는 정도로는 각자의 세상을 인정하고 내 세상에서는 이게 맞고, 당신 세상에서는 그게 맞다, 그리고 그걸 꼭 일치시킬 필요는 없다는 점만으로도 충분한 효과가 있다고 생각해요.
그래서 어쩌라고? (2)
내 의견이 맞다는 주장을 하고 싶거나, 타인의 의견이 틀렸다고 말하고 싶은 순간에, 해당 의견을 말하지 않습니다. 그 의견을 말하고 싶어 하는 본인 스스로를 바라보고 인식합니다. 이 의견을 표출해서 내가 얻는 이득은 무언지 따져봅니다. 과연 내가 맞아야 하는지 고민해 보고, 맞다고 할지라도 상대방이 틀린 걸 인정함으로써 얻게 되는 공통의 이익은 무엇인지 따져봅니다. 그 사이 잠깐의 호흡을 하는 것만으로도 큰 이익이 체감될 것입니다.
행복한 개발자가 되는 길 (1) — Breathwork
이건 제가 감히 명쾌히 다룰 수 없는 주제이겠습니다만, 요새 주된 관심사이다 보니 한 번쯤 글로 적어보면 좋겠다는 생각이 들었습니다. 저 스스로 정리해보고 모종의 다짐을 하는 목적이 크고, 어쩌면 누군가에게도 공감이 되는 내용이 있을 수 있겠다는 기대를 (아주 조금) 해봅니다.
행복을 추구하고, 불행을 걱정하기
너무 당연하게도, 모든 사람이 공통적으로 행복을 바라고 고통을 피합니다. 뭘 이루고자 한다거나 어떤 행동을 취한다거나 제자리에 앉아서 걱정을 한다거나 하는 행동의 배경에는 행복을 좇거나, 두려움을 떨치려는 의도가 있는 거죠.
행복하고자 하는 동기는, 가볍게는 지금 보다 더 행복해지고 싶다거나, 아니면 지금은 불행하지만 나중에는 행복해지고 싶다는 바람이 있습니다. 어느 쪽이든 지금은 충분히 행복하지 않다는 생각인 거죠. 예를 들어, 지금은 내가 신입 개발자지만, 열심히 공부하고 경험을 쌓아서 유능한 개발자가 되면 행복할 것 같다고 생각한다거나, 지금은 연약한 몸이지만, 운동으로 튼튼한 몸을 만들면 행복해 질 거라거나, 지금은 취준생이지만, 취업에 성공하면 행복할 거라는 기대 같은 것들이 있겠죠.
한편, 두려움의 배경에는, 지금은 그럭저럭 괜찮지만 자칫하면 불행해질 수도 있다는 걱정이 있습니다. 아니면 지금도 불행하지만, 더 불행해질 수 있다거나, 아니면 지금은 행복하지만 이 행복을 유지하려면 무언가를 열심히 해야 한다는 생각이 드는 것이 기본적입니다.
그렇게 되면 정말 행복한가?
개발자로 취업하면 행복한가요? 취준생 입장에서는 그렇게 기대하겠지만, 안타깝게도 막상 취업하면 이 회사가 괜찮은 건지 내 커리어는 어떻게 될 건지, 다음 직장은 어디로 노려야 하는지, 연봉이 적으면 적은 대로 많으면 많은 대로 또 다른 문제를 일으킵니다.
대기업에 입사한다거나, 네카라쿠배 취업해서 억대연봉받으면 행복할 것 같고, 아예 미국 FAANG으로 해외취업에 성공해서 해외파 개발자 인증을 받으면 행복할 것 같습니다. 내가 그렇게 된다는 생각만으로도 입가가 올라가고 행복할 것 같은 기대감이 일어납니다만, 정작 그런 입장이 현실인 사람들이 스스로 행복하다고 말하거나, 행복한 모습이 느껴지지는 않는다는 점이 흥미롭습니다. 그들의 조건은 당연한 것이 되고, 또 다른 불만이 그 자리를 대체합니다.
숨쉬기 운동으로 시작한, 사소하지만 신기한 경험
작년 말 즈음부터, 숨쉬기 운동(breathwork)를 기반으로 명상을 하고 있습니다. 숨쉬기 운동은 '윔 호프 호흡법' 같은 숨쉬기 방법을 가이드에 맞춰 따라하는 운동입니다. 유튜브에 'breathwork'로 검색하면 수많은 가이드 영상을 찾을 수 있습니다. 대략 15분 정도 따라 하기에 적당해요. (사람에 따라서는 안맞을 수도 있다고 하니, 처음에는 가벼이 실험적으로 접근해 보시는 정도가 좋을 것 같습니다.)
명상이 여러모로 좋다는 것은 익히 들어왔지만, 꾸준히 하기 힘들었는데, 숨쉬기 운동을 하고 나면, 명상 집중도가 높아져서 숨쉬기 운동 후에 명상을 이어서 할 수 있고, 명상이 잘 되고 나면 그 효과가 체감되어서 매일 지속적인 명상을 할 수 있게 됐습니다. 예전엔 명상이라면 5분도 하기 힘들었는데, 요즈음은 하루 서너 번 20분~40분씩 할 수 있어서 총 한두 시간씩 할애하고 있는 것 같습니다. 억지로 하려면 안되고, 효과가 체감되면서부터 좋아졌습니다. 사소하게는 시야가 밝아지고 머리가 맑아지는 체감이 즐겁습니다.
두어 달 밖에 안 됐는데, 몇 가지 사소하지만 신기한 체험을 몇 가지 경험했습니다. 공개적으로 적기에는 애매한 것들이지만, 그중에 하나는, '진정한 자아는 기본적으로 무한히 행복한 상태이다'라는 걸 아주 찰나의 순간에 느껴본 것 같다는 점이 있습니다. 그렇게 긴 순간도 아니었고, 명확하게 설명할 수 없는 경험이라서 확실하게 기술할 수 없어서 아쉽습니다.
암튼, 다양한 명상 서적이나 종교에서 이야기하는 인간의 기본은 행복한 상태인데 너 스스로가 고통을 감싸 쥐고 있다는 점을 더 경험으로 깨닫게 되면 좋겠다는 기대와 함께, 이런 생각이 들었습니다. '어쩌면 어떤 경험으로 더 잘 알게 될 수도 있겠지만, 일단 그 사람들이 얘기하는 걸 무작정 믿어본다면 어떨까?'
모두가 본디 평안한 상태라면
만약 그 참자아(true self)가 본디 더 할 것 없는 평안한 상태라면 '행복 추구'가 무의미해집니다. 지금 이미 덧붙일 수 없는 행복 상태인데 뭘 애써 더해서 행복을 추구하나요. 이미 모든 것을 이뤘으니, 더 이뤄야 할 무언가가 없다는 얘기인 거죠. 본능적 에고는, 지금 이럴 때가 아니라며 이런저런 걸 해야 하고, 그러려면 또 그에 앞서서 뭐뭐뭐를 해야 한다고 압박하고 들겠지만, 사실 그럴 필요가 전혀 없다는 얘기인 거죠.
그렇다고 현실적으로 아무것도 안 해도 되니까 가만있어라, 이런 뜻은 아닐 테고(그래도 상관은 없지만) 정말 무언가 하고 싶거나 해야 하니까 하는 거지, 미래의 행복을 위해서 억지로 해야 하는 상황이 아니게 된다는 뜻으로 이해해 보았습니다. 그런데 이게 참 편안해져요. 내가 뭔가 해야 했어야 하는 일들이 되게 많았는데, 해도 되지만 안 해도 된다는 사실만으로도 해방감이 느껴진달까요. 정말 꼭 해야 하는 일이 아니었던 거죠. 그중에 꼭 해야 하는 일들은 하고, 하고 싶은 건 하되, '막연히 행복해지기 위해 하려고 했던 별 쓸데없는 일들'을 버려버리는 겁니다.
개발자 뿐 아니라
이 관심사가 새삼 흥미로운 게, 삶의 모든 분야에서 다양하게 내가 뭘 (쓸데없이) 바라고 있었다는 점을 인식하게 된다는 점입니다. '쓸데없이 바라고 있었다'는 사실조차 인식하지 못했어요. 아까 잠깐 언급한 신기한 찰나에서 그 사실이 잠시 인식되자, 아 그게 무거운 마음이었다는 생각이 들고, 다시 그 찰나에서 빠져나오자 무거운 마음 상태가 기본이 되었습니다.
암튼, 행복해지려면 돈을 얼만큼 벌어야 하고, 건강은 어떻게 되어야 하고, 내 몸무게는 어떻게 되어야 하며, 아이 공부는 어떻게 했으면 좋겠고, 이런 지극히 정상적인 고민들의 관점이 대폭 흔들리는 상황입니다.
스스로는 어떻게 바뀌어갈지 흥미로운 상황입니다. 이미 뭔가 많이 바뀐 것 같아서 재밌고요. 그게 뭔지 모르겠습니다만 말이죠. 헛헛.
그래서 뭘 하라는 거야?
굳이 말해보자면, 꼭 그래야 하는 것은 아니지만 "숨쉬기 운동" 경험 추천드려 봅니다! 이미 명상이 잘 되시는 분들은 불필요할 것 같지만, 평소 명상에 관심이 있었는데 잡생각이 많이 끼어들어서 집중하기 힘들었던 분들에게 좋다고 생각해요.
달리기에서 배우는 괜찮은 개발자 되는 법
안녕하세요, 저는 오랜 경력의 백엔드 개발자입니다. 개발과는 별개로 건강을 위한 취미로 달리기를 시작한지 2년이 좀 넘었습니다. 달리기로 치자면 3년차 주니어 러너인 셈이지요. 가만히 보니까 제가 달리기를 하면서 배우고 있는 점들이 개발자 커리어에도 비슷하게 통할 것 같은 부분이 꽤 있더라구요. 그래서, 개발자 경력을 돌이켜봤을 때, 3년차 이하 개발자분들에게 도움이 될지도 모르는 팁을 공유해보려 합니다.
충분한 시간이 필요합니다
개발자하기로 마음 먹었으면 하루 빨리 실력있는 개발자가 되고 싶은 게 당연합니다. 달리기도 시작할 때는 꾸준히 운동하는 것만이 목표였지만, 어느새 잘뛰고 싶어지더라구요. 하지만 달리기라는 게 하루아침에 잘 뛰어지지가 않습니다. 충분한 기간을 두고 조금씩 늘려가야지, 급한 마음에 서둘러 마일리지를 늘리다가는 부상을 입기 십상입니다. 마음만 급하고 스트레스만 받고, 정작 실력은 늘지 않는 문제에 빠지는 거죠. 뛰기 시작해서 3개월만에 마라톤을 뛰고 싶을 수도 있지만, 그건 무리한 생각입니다. 되는 사람도 있겠지만, 대부분의 사람들은 그러다가는 부상을 입고 말 거예요.
개발자도 그렇습니다. 부트캠프 나오고 몇 개월만에 개발자 되고, 2년차에는 수퍼 주니어가 되고 싶은 게 기본입니다만, 그게 그렇게 짧은 시간에 되는 게 아닙니다. 꾸준히, 매일매일, 매주매주 마일리지를 쌓아나가다보면 어느새 실력있는 개발자가 되는 게 기본 루트일 것 같습니다.
초보 시절에는 초보임을 인정하고 급하지 않게 꾸준히 훈련하는 것이 중요하겠습니다.
내가 직접 해야 합니다
유튜브에 워낙 고품질의 정보가 많기 때문에 달리기도 배울만한 채널이 많습니다. 수많은 달리기 유튜브 채널들을 보며 어떻게 훈련해야 하는지, 달리기 자세는 어떻게 해야 하는지, 신발은 어떤 걸 신으면 좋은지 수두룩한 정보를 구할 수 있습니다. 그런 유익한 정보도 중요하지만, 정작 가장 중요한 것은, 나가서 뛰는 행위 자체입니다. 그 모든 걸 압도하는 중요한 부분이 본인이 달리는 거리입니다.
개발도 마찬가지입니다. 개발서적을 학습하고, 온라인 강의를 수강하고, 질문과 답변으로 학습하고 이런 일들이 꽤 도움이 되지만, 정말 정작 중요한 것은 내가 직접 개발해보는 행위입니다. 개발하는 행위 자체를 달리기 마일리지라고 치고 꾸준히 매일매일 쌓아가야 합니다. 꾸준히 하면서, 보조적으로 서적을 보며 수강도 하는 것이 맞겠습니다. 만날 책이나 강의만 보고 있는 것은, 유튜브에서 달리기 영상 보면서 끄덕끄덕하면서 정작 나가서 뛰지는 않는 행위나 마찬가지입니다. 말짱 꽝이죠.
훌륭한 다수의 의견이 내게는 중요치 않을 수 있습니다
나보다 나아보이는 다수의 개발자들이 이렇다저렇다 좋은 정보들을 줄 때가 많은데, 정작 그 정보들이 내게는 유효하지 않을 수도 있습니다.
달리기로 예를들면, 저같은 초보들이 흔히 빠지는 함정이, 신발은 뭘 신어야 하는지, 케이던스는 얼마로 뛰어야 좋은지, 발 착지법은 어떻게 가져가야 하는지, 물은 얼마마다 마셔야하는지, 팔동작은 어떻게 흔들어야 하는지, 별 사소한 팁들이 많습니다. 게다가 친절하게도 이 모든 정보들을 시시콜콜 알려주는 사람들이 많아요.
그런데, 열심히 정보를 취합하다보면, 어쩌면 저 정보들의 의미없겠다 싶을 때가 있습니다. 예를들어 케이던스를 놓고 보자면, 180정도가 가장 효율적이라고 하는데, 잘 뛰는 선수들이 180을 내는 거지, 내가 뛰는 속도에서 내 신체에서 과연 180이 최적인가는 의문이 있습니다. 그러니까, 선수급이 마라톤을 2시간 초반에 뛰는 속도에서 최적인건데, 내가 2시간대에 마라톤을 뛸 수 있을리 만무합니다. 내가 그런 부차적 지표에 기준을 삼아서 노력하는 것은 무의미할 수도 있겠다 싶습니다.
그런데 어설픈 상식수준에서는 그게 그럴싸해 보이잖아요? 엘리트 선수들 보면 보통 180케이던스를 유지하더라. 그리고 실험한 결과를 보면 케이던스가 180근처인 게 가장 효과적이더라라는 결과들도 있겠죠. 근데 그게 그렇다고 억지로 케이던스를 180에 맞추는 게, 초보인 내 입장에서 달리기 마일리지보다 더 중요하냐?는 건 의심해봐야 하겠습니다.
개발자 입장에서, 뭐는 이렇게 해야하고 저건 이렇게 해야 한다는 주장들을 접할 때가 많은데요, 은근 빈번하게 별 쓸데 없는 고민에 시간 낭비하고 있는 경우가 많습니다. 한번쯤 정말 도움이 되는 얘기인가 고민해 볼 필요가 있다고 생각해요.
달리기만 할 수는 없습니다
하루라도 빨리 좋은 개발자가 되기위해, 잠 줄여가며 노력하고 싶을 때도 있습니다. 하지만, 이게 장기전이기 때문에 단거리 달리기 하듯 계속 달릴 수는 없어요. 게다가 달리기 실력이 느는 것은 훈련시간 자체가 아니라, 훈련 후에 잘먹고 잘 쉴 때, 특히 잘 때 늡니다. 잘 자야 한다는 얘기예요. 잘 시간 줄여서 달리는 건, 잘 몰라서 하는 바보 같은 일이죠.
개발도, 너무 개발만 몰입해서는 개발실력이 늘리 없습니다. 잘 자는 건 당연하고, 개발 외의 공부들도 병행해 줘야 합니다. 잠 줄여서 개발 공부한다? 이것도 어리석은 일입니다. 공부했으면 잘 자야 머리속에서 정리가 되는 거죠.
재미가 있으면 훨씬 편합니다
처음에는 작심삼일을 여러번 하겠다고 달리기를 이악물고 시작했습니다. 의지박약인 내가 꾸준히 달리리면 정신 바짝차리고 열심히 해야 하는 거죠. 아무리 강한 의지력을 발휘한다고 해도, 사람인 이상 한계가 있습니다. 의지력만으로 1주일에 60K를 뛴다? 불가능한 일이라고 보겠습니다. 그럼 어떻게 이 지경(?)이 됐냐? 달리기 자체가 재밌어졌기 때문입니다. 재밌으면 지속하기가 훨씬 편합니다. 달리기가 재밌을 줄은 몰랐습니다.
남들은 개발을 어떻게 시작하게 됐는지는 몰라도, 적어도 제가 보기에 대단히 재밌는 활동입니다. 이 재미를 찾지 못하면 꾸준히 하기 너무 힘들지 않겠어요? 달리기는 하다 말면 그만이지만, 직업 개발자가 되기로 했다면 내 커리어 수십년 동안 해야 하는데, 이걸 이 악물고 꾸준히 열심히 한다? 너무 어려운 길이죠. 재미를 붙여서 하는 게 맞겠습니다. 재미가 있으면 누가 시키지 않아도 열심히 하겠죠.
그러니 그냥 막무가내로 열심히만 할 게 아니라, 재밌게 하는 방법을 고민해봐야 하겠습니다. 흔한 자료들은 “재미”에는 큰 중심을 두지 않기 때문에, 아쉽게도 각자 스스로 재미 포인트를 찾아야 하는 상황인 것 같습니다. 억지로 열심히 해서 잘하는 사람들도 많겠지만, 나도 꼭 그래야 하는 건 아닙니다. 재밌게해서 잘해도 되는 거, 아니 더 좋은 거잖아요.
확실한 것은, 재미있는 것은 맞습니다. 그러니까 제가 이렇게 오랫동안 하고 있는 거겠죠. 정확히 말하자면, 재미 없으면 안하는 것이 맞겠습니다. 왜 힘들게 재미 없는 걸 계속 공부하며 노력을 해야 하나요? (늘 재밌는 건 아니지만, 꾸준히 할만큼 재밌는 포인트는 반드시 있어야 합니다)
비교는 정신건강에 해롭습니다
달리기는 기록이 정확히 드러나기 때문에 남들과 비교하기 쉽습니다. 나는 어느 정도 속도로 얼마나 뛸 수 있는데, 저 사람은 어떻지? 내가 더 잘 뛰나? 저 사람이 더 잘 뛰나? 이런 비교는 내 달리기 본연의 목적과 다를 수 있습니다. 더 빠르고 느리고를 기준으로 삼으면 항상 누군가는 나보다 빠르기 마련이고 그럼 난 또 그 사람보다 못한 사람이 되는 논리에 빠지게 되는 거죠. 대회를 나가더라도 “완주”에 중점을 둔다면 참가자 대부분이 즐거운 결과를 누릴 수 있는데, “1등”을 노린다면, 그 1등은 행복할지 몰라도 나머지 절대 다수의 참가자들은 들러리가 되는 거 아닐까요?
개발자가 되려는데 남들보다 잘하는 개발자, 최고의 개발자가 되는 것이 목표라면, 이건 스스로를 이미 고문하는 감옥에 가두고 시작하는 꼴입니다.
달리기로 치자면, 지난 달의 나보다 잘 뛰게 되었을 때의 기쁨을 만끽한다거나, 아니면 꾸준히 뛰는 것만으로 만족할 수 있다면 지속적으로 즐겁게 달릴 수 있습니다. 애초에 달리기를 시작한 목적도 건강에 도움이 되는 활동이라는 것이기 때문에 그 목적은 대단히 초과달성하고 있는 거죠.
개발자로 치자면, 어떤 기준을 갖고 방향을 잡을지 스스로 잘 고민해보면 좋겠습니다.
꾸준함이 제일 중요합니다
달리기 실력이 느는 가장 중요한 팩터는 꾸준히 달리는 행위입니다. 어느 날 반짝 열심히 달린다거나, 어느 날 하루 오래 달린다고 해서, 갑자기 실력이 늘지 않습니다. 오랫동안 꾸준히 지속적으로 노력해야(즐겨야) 어느 순간 실력이 늡니다.
개발도 꾸준히 수련해야 합니다. 어느날 반짝 노력하거나 비기를 획득한다고 되는 게 아니니 끈기를 갖고, 재미를 붙여 오랫동안 열심히 할 마음으로 지내면 좋다고 생각해요.
내가 그리 대단치 않습니다
달리기 시작할 때는, 제가 그래도 어려서 육상 선수였는데 조금만 하면 잘 할 줄 알았습니다. 근데 뭐 당연하게도 한참 못 뛰더라구요. 오래달리기는 그야말로 마일리지가 깡패입니다. 많이 뛰면 뛴 만큼 잘하게 되어있습니다. 마일리지를 일단 채워두고 거기서 실력이 나누어지기야 하겠지만, 일단 초보된 입장에서는 오로지 달리기 마일리지만이 핵심입니다. 평소 다른 운동을 잘했건 어려서 육상선수였건 말건 이딴 건 아무런 도움이 되지 않습니다. 그저 초보된 입장에서 차근차근 쌓아 올려야 합니다.
개발도 그렇습니다. 우리가 어떤 다른 분야에서 날고 기었다 한들, 새로 시작했으면 생초보입니다. 겸손하게 난 아무것도 아니라는 시작점에서 차근히 여유롭게 나아가면 됩니다. 지나치게 기죽을 필요도 없지만, 그렇다고 강한 에고를 내세워서 좋을 것도 없겠습니다.
이상, 달리기와 개발을 좀 억지로 엮어서 팁을 적어보았습니다. 뛰어난 러너도 아니고 훌륭한 개발자도 아니면서 이렇다저렇다 적으니 부끄럽습니다만, 공감되는 부분이 있으셨으면 좋겠습니다. 긴 글 읽어주셔서 고맙습니다.

AWS에 서버리스 Rust로 수익 알리미 만든 이야기
제가 뭔가 판매하는 어떤 웹사이트에서 발생한 수익을 그때그때 알고 싶었습니다. 이 수익 발생 이벤트를 제 휴대폰으로 즉시 알려주는 시스템을 구축한 이야기를 공유합니다. AWS 환경에서 서버리스(Serverless)로 간단한 알림 시스템을 Rust로 만든 이야기입니다. AWS의 많은 기능 중 이런 것도 있어서 유용하게 쓸 수 있다는 정보가 되리라 기대합니다.
내용
- (목표) 무얼 왜 만들려 했나?
- (수단) 뭘로 만들었나? 왜 그걸로 만들었나? 뭐가 좋았나?
- (경험) Rust를 왜 써봤나? 뭐가 좋던가?
- (추천) AWS Lambda, EventBridge, SNS, DynamoDB 이용후기
원하는 결과물
몇 달 전부터, 온라인에서 뭔가 팔기 시작했습니다. 아쉽게도 비공개 API를 써야 하는지라 어떤 웹사이트인지를 말씀드리기는 조심스럽습니다. 아무튼, 어떤 웹사이트에서 판매 수익이 발생하면, 그 수익을 곧바로 알고 싶더군요. 가끔씩 해당 웹사이트에 들어가서 수익금 현황 페이지를 새로고침하다가, 내가 가서 확인하는 게 아니라, 발생할 때마다 내 휴대폰으로 알림이 왔으면 좋겠다는 생각이 든 거죠.
- 판매 이벤트가 발생하면 내 휴대폰으로 알림을 받아보자.
어떻게 알림을 받을까?
가만 째려보니, 아래와 같은 구조로 개발하면 되겠다는 그림이 나왔습니다.

큰 관점에서 보면 위 그림으로 구현하면 될 것 같았고, 세부적인 내용은 AWS에서 제공하는 서비스들의 특성을 활용해서 조정해 가며 개발하기로 마음먹었습니다.
AWS Lambda 함수
AWS 람다 서비스는, 어떤 이벤트에 발생할 때, 내가 등록해 놓은 함수를 실행할 수 있는데, 함수는 다양한 언어로 작성할 수 있습니다. 자바나 파이썬, 자바스크립트는 물론이고, 다양한 언어환경을 기본으로 지원합니다. 인스턴스를 미리 하루종일 실행하는 것이 아니라, 함수를 등록해 놓으면, 이벤트에 대응해 실행한 시간만큼만 과금되는 서비스입니다. EC2나 라이트세일 같은 서비스의 인스턴스는 아무리 작은 인스턴스를 띄워도 내내 띄워두면 개인 사이드프로젝트 입장에서는 적지 않은 비용이 발생하는 부담이 있습니다만, 람다 같은 경우 사실상 거의 비용이 발생하지 않는 매력이 있습니다.

Rust 프로그래밍 언어
최근 Rust프로그래밍 언어를 조금 공부했습니다. 고성능의 저수준 프로그래밍을 할 수 있으면서, 언어 자체는 매우 고수준이라서 마음에 쏙 들었습니다. 기회가 되면 적극 활용해보고 싶다는 생각이 들었는데, 이번이 기회다 싶었습니다.

이번에는 람다 함수를 Rust언어로 작성해 보기로 마음먹었습니다. 기존에는 Scala랑 TypeScript(node.js)로 만들어서 배포해 본 경험이 있어요.
새로운 언어 적용 기회
새로운 언어를 적용하려면 새로 익혀야 할 것도 많고 시간이 오래 걸리기 마련입니다. 언어만 새로 알면 되는 게 아니라, 그 언어에서 주로 쓰는 주요 프레임워크들을 같이 공부해야 하는 시간과 노력이 꽤 필요해서, 이미 익숙한 언어와 프레임워크를 쓰는 게 더 현명한 판단일 가능성이 높습니다.
하지만, Rust를 새로 공부하기로 마음먹었으니, 이 좋은 기회를 살려야겠죠. 다행히 Rust언어 같은 경우 AWS에서 꽤 공격적으로 지원해 주려는 것으로 추측됩니다. 무려 공식 SDK가 있어요. (아직 개발자 프리뷰 버전입니다만 그게 어딘가요?!)
이번에도, 사실은 너무 오랜 시간이 걸릴 것 같으면 중도에 포기하고 그냥 스칼라로 개발하려고 했습니다만, 하고자 하는 작업이 간단했던 데다, Rust로 진행해 보니 생각보다 진척이 빨라서 무리 없이 끝까지 마무리할 수 있었습니다.
Cargo Lambda
Rust는 기본으로 포함된 cargo라는 패키지 매니저를 쓰는데, 이 cargo라는 툴의 플러그인 중에 AWS Lambda 서비스를 개발하고 배포하는데 특화된 게 있습니다.
Cargo Lambda is a subcommand for Cargo, the Rust package manager, to work with AWS Lambda.
Cargo Lambda provides tools and workflows to help you get started building Rust functions for AWS Lambda from scratch. When you're ready to put your work in production, Cargo Lambda helps you build and deploy your functions on AWS Lambda in an efficient manner.
https://www.cargo-lambda.info/
별다른 고민 없이 해당 플러그인에 있는 커맨드로 로컬에서 테스트해 보고, 람다함수로 배포하기도 쉬웠습니다. 새로운 언어를 쓰더라도, 실무 환경에 있는 사람들이 많이 쓰기 시작하면 문제없이 적용할 수 있게 되는 것 같습니다. Rust는 그런 면에서 충분한 합격점인 상황입니다.
AWS SDK for Rust
 https://awslabs.github.io/aws-sdk-rust/
https://awslabs.github.io/aws-sdk-rust/
아직, 개발자 프리뷰상태이니 프로덕션 환경에서 쓰지 말라는 경고가 붙어있기는 합니다만, 그래도 AWS에서 공식적으로 만들어준 SDK가 있습니다. 평소 마이너 언어를 종종 쓰는 입장이다 보니, 공식 SDK의 존재가 새삼 감사하게 느껴집니다. 덕분에 Rust 환경에서 편리하게 AWS서비스에 접근할 수 있었습니다.
AWS EventBridge
이번에 처음 알게 된 서비스인데, AWS EventBridge라는 서비스가 있습니다. 이 EventBridge 서비스 안에 Scheduler라는 기능이 들어있어서, 이 기능을 통해 특정 시점이나 반복주기에 맞게 이벤트를 발행할 수 있습니다.
 https://aws.amazon.com/ko/eventbridge/
https://aws.amazon.com/ko/eventbridge/
여기에 매 10분마다 특정 AWS Lambda함수를 실행하게끔 등록해 두었습니다.
람다 함수 (1) - 목표 API를 폴링해서 신규 판매실적을 파악하자
이번 시스템은 간단한 람다 함수 2개로 구성했습니다. 첫 번째 함수는, 실행되면 목적 API에 접근해 JSON데이터를 읽어서 그중 새로운 판매정보를 읽는 역할을 담당하게 했어요. 위에 소개한 EventBridge에 등록해 둔 스케줄에 따라서 이 람다함수를 실행하고, 이 람다함수는 새로운 판매실적 정보를 기록하고 알림을 보낼 수 있도록 했어요.

이 첫 번째 람다함수가 매 10분마다 목표 API를 조회해서, 새 판매실적에 대해서만 SNS 토픽에 메시지로 발행하는 역할을 담당했어요. Rust로 개발하는 작업이 처음이라 조금 시간이 걸렸지만, 그래도 생각보다는 금방 결과물이 나왔습니다. 이 함수 개발에만 하루 쓴 것 같네요.
신규 데이터 확인
조회하고자 하는 비공식 API는 최근순서로 N건의 판매건수를 조회할 수 있었습니다.
[
{"amount": 10000, "at": "2023-08-11T02:30:00Z"},
{"amount": 11000, "at": "2023-08-10T12:00:00Z"}
]
이런 식으로 판매 실적이 담겨있었는데, 아쉽게도 PK 값으로 추정되는 건 따로 보이지는 않았습니다. 아쉬운 대로 몇 가지 고유해 보이는 값들을 조합해서 해쉬값을 만들어서 임의의 PK값을 만들어서 쓰기로 했습니다. 해당 데이터를 AWS DynamoDB 테이블에 넣어두고, 나름의 방식으로 생성한 PK값을 기준으로 기존 데이터인지 신규 데이터인지 파악하도록 합니다. 이미 기록된 판매실적이라면 무시하면 되겠죠.
AWS DynamoDB
 https://aws.amazon.com/ko/pm/dynamodb
https://aws.amazon.com/ko/pm/dynamodb
AWS DynamoDB는 AWS가 관리해 주는 NoSQL데이터베이스인데, 이런 간단한 서비스에 활용하기에 매우 좋은 것 같습니다. 본래 목적은 대규모 트래픽에 유연하게 대처하는 데이터베이스 서비스입니다. 접근량이나 데이터 규모에 맞게 과금되는 식이라, 이처럼 작은 서비스에서 조금의 데이터만 활용하게 되면, 사실상 비용이 발생하지 않아서 더욱 매력적입니다. 아무리 작은 RDB인스턴스라도 개인 수준에서 비용은 적지가 않은데, 성능도 빠르게 쓸 수 있어서 아주 좋습니다.
AWS SNS
 https://aws.amazon.com/ko/sns/
https://aws.amazon.com/ko/sns/
AWS SNS 서비스는 메시지 버스로 활용할 수 있습니다. 이벤트 메시지를 발행하면, 해당 토픽을 구독하고 있는 대상들에게 메시지가 전달됩니다. 토픽을 구독하는 대상은 다양한 종류가 올 수 있는데, 저는 Email과 Lambda실행을 연결해 두었습니다. 새로운 판매실적데이터가 특정 SNS토픽에 전달되면, 그 토픽을 구독하고 있는 이메일 주소로 해당 데이터가 메일로 발송되고, 지정한 람다함수(2)도 실행하도록 설정했습니다.
두 번째 람다함수를 개발하는 과정에는 이메일로만 구독해서, 신규 판매실적이 메시지로 잘 발행되는지를 확인하며 진행했고, 람다함수(2)의 경우 제가 이용하는 슬랙 채널에 메시지를 발행하도록 했어요.
람다함수 (2) - 신규 판매 실적을 내 휴대폰으로 알리자
두 번째 람다 함수는 이미 만든 첫번째 람다 함수를 살짝 바꾸면 됐기 때문에 금방 만들었습니다. SNS Topic에 구독하는 항목 중에 Lambda 함수를 실행할 수 있는 항목이 기본으로 있고, 특정 람다함수를 실행하면서 SNS에 전달된 메시지를 전달할 수 있습니다. 그럼 Lambda함수 입장에서는 해당 메시지를 읽어서 원하는 처리를 할 수 있게 됩니다. 어떤 서비스를 이용해서 제 휴대폰으로 메시지를 보낼까 생각해 보니, 곧바로 떠오르는 것은 카카오톡과 슬랙이었습니다. 카톡으로 메시지를 받으면 편리하겠는데, 개발자 문서를 좀 뒤져보니, 좀 시간이 걸릴 것 같습니다. 일단 예전에 연결해 봤던 슬랙을 쓰기로 합니다.

슬랙도 워낙 많이 쓰는 서비스이니까, 잘 찾아보면 SNS 토픽 구독해서 슬랙 메시지로 발행해 주는 기능이나 누군가 이미 만들어 공개해 둔 Lambda함수를 가져다 쓸 수 있을 것 같았지만, 뭐 어려운 기능은 아니니까 애써 찾느니 그냥 만들기로 합니다.
첫번째 람다함수를 좀 손봐서, 슬랙 메시지 발행하는 람다함수로 만들었어요.
전체 구조
두 파트로 나눠서 그렸던 전체 구조를 다시 그리면 아래와 같습니다.

람다 함수로 기능을 잘게 쪼개서 작은 일들만 처리하게 한 점이 제게는 재밌었습니다.
결론 및 정리
서버리스 시스템 참 편리한 것 같습니다. 이미 있는 탄탄한 서비스들에 설정만 걸어서, 내가 원하는 작업을 하되, 요금 비용과 시간 비용을 모두 절약할 수 있는 환경이라고 생각합니다.
과거 근무한 환경에서는 카프카나 별도 MQ도 쓰고 했었지만, 요새는 클라우드 환경에 이미 잘 갖춰진 메시지 버스나 큐 시스템이 있기 때문에 별도로 고민할 필요 없이 잘 쓰기만 하면 되는 상황이라 편리합니다.
러스트로 람다 함수를 만들어서 쓰는 것은 종종 더 해볼 것 같습니다. 이 글을 정리하는 동안 슬랙 알림을 한 건 받았습니다. 어쩌다 한 건 받으니까 더 자주 알고 싶어서 이런 시스템을 만들어봤나 봅니다. 사실 판매량이 많으면, 하루에 한번 총 판매액만 보면 될 텐데 말이죠.
암튼, AWS 서버리스 환경을 아직 안써보신 분들께는 한번 써보시는 것도 좋겠다고 추천드리면서 글을 마치겠습니다.
감사합니다.
2023년 8월 11일 작성
프로 함수형 프로그래머, 괜찮나?
이 글은 직업 함수형 프로그래머로서 느끼고 있는 회의감을 토로한 것으로, 다소 어두운 분위기일 수 있는 점 미리 말씀드립니다. 글 끝자락에라도 빛기운이 들기를 바라봅니다.
프로 개발자
프로 운동선수를 생각하면, 그 기준이 상당히 까다롭겠습니다. 프로 리그에서 현역으로 뛰고 있는 선수여야 한다거나, 아니면 프로 선수 자격증을 취득해야 한다거나 하는 명확하고 높은 기준이 있겠죠.
하지만, 제가 삼고 있는 프로 개발자의 기준은 간단합니다. 개발을 하면서 월급, 그러니까 가계소득을 챙기고 있으면 그게 프로인 거죠. 프로의 마음가짐이나 실력을 따지기 시작하면 너무 모호해지기 쉽잖아요? 어차피 프로 개발자 리그가 있지 않은 이상, 필요 주 소득원이 해당 개발 일로 발생하면 그게 프로 개발자인 겁니다. 그저 월급을 받을 수 있는 직업 개발자이면 되는 거죠. 이 기준에 따르면 실력 좋은 학생이나 예비 개발자도 프로는 아닙니다. 역으로 실력이 없더라도, 월급을 잘 받고 있다면 프로인 거죠. 간단하죠?
프로 함수형 개발자
그런 기준에서 프로 함수형 프로그래머로서 업으로 함수형 프로그래밍을 하는 호사를 누린 지 꽤 됐습니다. 클로저와 스칼라에 이어서 하스켈까지 업무로 활용하는 팔자 좋은 생활을 했습니다.
어떤 분들은 제가 덕업일치를 이루어 살고 있다고 말해주기도 하지만, 결론부터 말하자면, 이 호화로운 사치를 계속하는 게 맞는가 하는 의문이 들기 시작했습니다. (이제야?)
프로 클로저 개발을 했던 회사는 해당 프로젝트를 자바로 전환하는 일을 고심(or 진행) 중이라 합니다. 프로 스칼라 개발을 했던 팀은, 해당 프로젝트를 타 팀으로 이관하지 못해서 유지보수의 책임을 지고 있다 합니다. 하스켈로 일하고 있는 현재 회사는 현재 진행형이지만, 제 개인적으로는 하스켈의 어려운 점을 하나 둘 인정하고 있는 단계입니다.
인프콘 2023 발표 예정
함수형 프로그래밍 언어로 대표 격인 세 가지 언어를, 직업적으로 해본 경험을 주제로, 올해 8월 인프콘 콘퍼런스에서 발표하기로 했습니다. 흔히, 콘퍼런스에서 발표하는 내용은 뭔가를 이렇게 이렇게 잘했다고 공유하는 것이 보통인 것 같은데, 아쉽게도 잘했다고 자랑하기는 어려울 것 같습니다.
그렇다고 실패담이라고 하기는 아쉬우니 경험담 수준에서 최대한 밝게 다뤄보려고 합니다. 재밌는 발표가 될 수 있기를 기대합니다.
스칼라 기초 강의 제작
며칠 전, "자바 개발자를 위한 스칼라"라는 온라인 강의 영상을 만들어서, 인프런에 등록했습니다. 검수과정이 잘 끝나면, 6월 초부터는 구매가 가능할 것 같습니다. 과연 몇 분이나 구매해서 들어주실지 모르겠지만, 아마도 구매수가 많지는 않을 것 같습니다. 강의의 가치 판단은 미뤄보더라도, 일단 "스칼라"에 대한 사람들의 관심이 많지 않을 테니 구매량에 대한 고민을 크게 할 수는 없을 것 같습니다.
수요는 많지 않겠지만, 그래도 관심 있는 주제에 대해 강의를 하나 다 만들 수 있어서 스스로 기특하다 칭찬하고 있습니다. 차차 더 유용한 강의를 만들 수 있는 계단 하나 쌓은 거죠.
다음 강의 주제를 고민하던 중...
강의 제작을 더 진지하게 도전해 보려고 이런저런 고민을 해봤습니다. 첫 강의가 아직 공개되기도 전입니다만, 곧바로 다음 강의를 만들 준비를 시작했습니다.
딱 떠오른 것은 "속성 기반 테스팅"이었고, 이를 주제로 스칼라, 자바, 자바스크립트 등에서 각 언어에서 널리 쓰이는 속성 기반 테스팅 라이브러리를 소개하고 쓰는 법을 공유하는 강의를 만들면 유용하겠다는 생각이 든 거죠.
그런데 잠깐! "속성 기반 테스팅"이라는 주제 자체가 너무 생소하다는 점에서 주춤하게 되었습니다. 사람들에게 관심 있는 주제를 강의로 만들어야, 수익성이 있을 테고, 제게 수익이 중요한 상황이니, 응당 "관심 있는 주제"를 공략해야 하겠습니다. "속성 기반 테스팅"이 수익성이 있을까요? 의외로 수익성이 있을 수도 있겠지만, 아마 기본은 저조한 수준일 겁니다.
내가 하고 싶은 강의가 곧 사람들에게 관심 있는 주제라면 좋겠지만, 그렇지 않다면, 수익성은 크게 고민하지 말고, 자아만족이나 사회공헌의 느낌으로 가져가야 하겠죠. 지금 제가 거창하게 사회공헌을 논할 상황이냐? 아쉽게도 그렇지 못한 것 같습니다. 경제적 독립을 이뤄냈고, 은퇴 비슷한 걸 한 상황이라면 모르겠지만 말입니다.
BETA vs. VHS 교훈
오래전에 비디오테이프라는 매체가 있던 시절에, 소니에서 베타라는 비디오테이프 규격을 내놓았고, 경쟁 규격으로 VHS라는 게 있었다 합니다. (어릴 때 저희 집에 베타 비디오 플레이어가 있었던 것 같지만, 그걸 얘기하면 제 나이가 너무 드러나므로, 일단 은근슬쩍 넘어갑시다)
암튼, 기술적으로는 VHS보다 베타가 여러모로 앞서있었다 합니다. 그런데 여러 기술 외적 이유로 인해, 베타는 시장에서 사라지고, VHS가 비디오테이프 시장을 주름잡게 됩니다. 비디오테이프 매체라는 기준에서, 기술 스펙이 우월한 것만으로는 시장에서 승리하는 데에 충분치 못했던 거죠.
함수형 프로그래밍이 기존 명령형 프로그래밍에 비해, 기술적으로나 학술적으로나 여러모로 우월하다고 봅니다. 이 의견 자체도 논란의 여지가 있을 테지만, 관대하게 봐줘서 사실이라고 쳐도 그 기술적 우월함이, 프로그래밍 패러다임 시장에서 의미 있게 팔리는 것과는 별개일 수 있다는 겁니다.
지금 시장에서 널리 쓰이는 패러다임은 파이썬, 자바, 자바스크립트 등 주류 언어가 자리 잡고 있는 명령형 프로그래밍입니다. 함수형 프로그래밍 패러다임은, 각 주류 언어들 안에서 제한적으로 조금씩 쓰이는 수준이 기본 현실이겠습니다.
함수형 프로그래밍은 BETA의 길을 갈까?
마음으로는 아니라고 믿고 싶지만, 현실적으로는 부인하기 어렵습니다. 하스켈, 클로저 같은 언어들은, 계속 비주류의 길을 가겠죠. 하스켈은 계속 학계에서나 쓰일 것 같고, 클로저는 아주 일부의 팔자 좋은 능력자들만 계속 쓰게 될 것 같습니다. 그마저도 해외에서나 가능할 테고요.
그리고, 한 가지 더 말씀드리자면, 그 커뮤니티 사람들은 소수가 이용하는 현실에 큰 불만이 없습니다. 오히려 너무 초심자들이 많아지면, 그 무게가 너무 무거워지기도 하거든요. 쓸 사람만 쓰는 현실을 받아들이는 것 같습니다.
아무튼, 함수형 프로그래밍 언어들에 있는 좋은 접근들이 다른 주류 언어에 긍정적 영향으로 전파되기야 하겠지만, 그 자체로 주류 언어가 된다? 그런 일은 없을 겁니다. 하스켈이 주류가 된다는 말은, 에스페란토가 만국 공용어가 될 거다라는 주장과 비슷한 수준이지 않을까 합니다.
그래도 BETA처럼 아예 없어지지는 않을 겁니다. 앞으로도 소수의 비주류로 지속되며, 주류 언어에 영향을 끼치며 나아가겠죠.
적자생존
최고의 유전자들이 살아남는 게 아니라, 환경에 적합한 유전자들이 살아남는 거고, 함수형 프로그래밍은 현재 직업 개발자 환경에서 적합하다고 보기는 어렵겠습니다.
분명 탄탄한 프로그램을 짜는 데 우월하지만, 현업 개발환경은 그렇게까지 어렵게 탄탄함을 추구하지는 않습니다. 당장 (누구나) 빠르게 만들어 내는 편리함을 추구하는 게 현업의 환경이죠. 코파일럿이나 GPT 등이 빠르게 안내해 주는 코드를 복붙 하는 시대인 상황에, 힘겹게 코드 정합성을 수식 증명하듯 꼼꼼하게 하고 있는 건 시대착오적인 행동인 것 같기도 합니다.
개인 프로젝트의 영역에서는...
아마도 개인 프로젝트의 영역에서는 계속 스칼라나, Elm 같은 함수형 프로그래밍 언어들을 더 쓸 것 같습니다. 혼자 만들어도 되는 범위에 있어서는 분명 훨씬 나은 점이 도드라진다는 믿음이 있습니다.
하지만, 여러 인원이 모여서 함께 일해야 하는 환경이라면, 함수형 프로그래머를 구하는 것 자체가 어려운 일이므로, 취미나 개인 프로젝트 사이, 좀 더 넓힌다면, 뜻 맞는 몇 명이 소규모로 모여서 작고 탄탄한 프로젝트를 진행할 때는 요긴하고 감사히 쓰기야 하겠죠.
그래서 함수형 프로그래밍 경험을 후회하는가?
아마, 저는 또 비슷한 선택을 할 수 있더라도 비슷한 과정을 거치게 될 것 같습니다. 한편으로는, 그 세 가지 함수형 프로그래밍 언어를 직업적으로 활용할 수 있었던 현실에 감사하고 있습니다. 뭔가 새로운 언어를 배울 때 흔한 걸림돌 중 하나가, "어디 써먹을 일이 없어서 잘 배우기가 어렵다"는 점인데, 전 실용의 영역에서 나름 실전적으로 배울 수 있었던 거죠.
마음 한 편에서는, 그저 취미나 학습, 그리고 기호의 영역에서 순수하게(?) 공부로 접근했으면 어땠을까 하는 생각을 하기도 합니다. 직업 개발은 남들 다 쓰는 주류로 하고 말이죠. 취미로 글을 쓴다거나, 강의를 만든다거나 하는 정도는, 개인 시간에 틈틈이 진행하면 좋을 것 같습니다.
아무리 좋은 기술이라고 해도, 동료들이 쓰지 않는다면, 그 의미가 급격히 줄어드니까 말이죠. 어쩌면 그렇게 좋은 기술이 아닐지도 모르고요.
마무리
그래서, 혹시 함수형 프로그래밍 언어에 관심이 많으신 분들께 응원의 말씀을 남긴다면, "계속 취미나 지적 호기심의 영역에서 학습하는 것"도 충분이 의미가 있다 말씀드려보겠습니다.
스스로도, 계속 공부와 실험의 영역, 개인 프로젝트에서의 실용은 계속해 나아갈 테고요.
스칼라 미니북 공개

함수형 프로그래밍에 관심을 두다, 클로저, 스칼라, 하스켈을 차례로 업무에 활용하고 있습니다. 셋 다 널리 쓰이는 함수형 프로그래밍 언어인데, 셋이 생각보다 많이 다릅니다.
다 매력적이지만, 현대 백엔드 개발에서는 그중 가장 스칼라가 실용적이라는 생각을 하고 있습니다. 하스켈은 too much인 것 같습니다.
스칼라 정도면 함수형 프로그래밍도 꽤 본격적으로 할 수 있으면서, 현업 환경을 떠나지 않고도 실제 활용이 가능하다고 봅니다.
그런 생각에 이어, 기존 자바 개발자들을 대상으로 스칼라를 소개하는 미니 웹북을 만들었어요.
보시는 분들은, 워낙 간단하고 짧아서 쉽게 읽으실 수 있을 텐데요, 저로서는 인생 첫 책이기도 하고, 게으른 성격에 뭔가 길게 가져가다가 마무리한 점에서 꽤 뿌듯합니다.
스칼라에 흥미가 있으시다면, 일독 부탁드리겠습니다.
감사합니다.
온라인 무료 미니북 주소
3시간 만에 다 배우는 Elm 가이드 영상
웹 애플리케이션 프론트엔드 개발용 언어로, Elm을 몇 번 써보았습니다. 함수형 프로그래밍을 공부하는 입장에서 꽤 매력적이다 느끼게 되어, 다른 분들께도 소개하고 싶다는 마음이 일었습니다.
저는 2018년도에 처음 알게된 프로그래밍 언어인데, 그때도 마음에 들었던 나머지, 소개하는 글을 한 편 올렸었네요.
Elm — 웹 앱 전문 함수형 프로그래밍 언어 소개글 링크
최근에도 사내용 관리툴을 만들 때 사용해봤는데, 이제는 하스켈을 공부한 다음이라서인지, Elm의 간결함이 더 매력적으로 느껴집니다. Elm의 매력을 3가지만 미리 꼽아보자면,
웹 애플리케이션 개발의 틀이 탄탄하게 잘 잡혀있어서, 그대로 따라서 개발하기 좋습니다. 강한 정적 타입 언어로 컴파일 시간에 모든 에러를 다룹니다. 런타임 에러가 발생하지 않습니다. 순수 함수형 프로그래밍 언어이면서도, 문법이 대단히 간단합니다. 이번에는, 공식 가이드 문서 전체를 다시 공부하며, 영상으로 남겨보았습니다. 무려 3시간짜리 영상을 다 봐주실 분은 거의 없겠지만, 그래도 Elm을 공부하시려는 분들에게는 조금이나마 도움이 됐으면 좋겠다는 바람입니다.
감사합니다.
작성일: 2023년 1월 1일
근로 소득 개발자
출근길에, 은행에서 카톡이 왔습니다. 급여가 입금되었다는 반가운 알림이었습니다. 월급이 매달 입금되는 것이 근로자 입장에서 가장 중요한 일이겠습니다. 중요하고 감사한 일인데, 매달 따박따박 입금되는 것이 당연해지고, 당연해지고 나면 그 밖에도 다른 욕심들이 자라나기 마련입니다.
예를 들면, 나는 회사에서 얼마나 공헌하며, 인정받고 다니고 있는가, 나는 여기서 뭘 배우며 얼마나 성장하고 있나, 내가 원하는 일을 하고 있나, 회사는 나를 필요로 하는가, 또는 나는 어떻게 이 세상을 이롭게 바꾸고 있는가 등등등. 각자의 가치관에 따라 얼마든지 다를 수 있는 다 중요한 가치들이 있겠습니다.
좋은 현상인지 나쁜 현상인지 모르겠습니다만, 오랜 기간 월급을 받다 보니, 그 가치들에 대한 관점이 제 삶에 있어서 중요한 부분으로 최소화되는 것 같습니다. 예를 들어, 배우며 성장하기 같은 주제는, 한창 열 일하는 개발자분들에게는 너무도 중요하고 관심 가는 가치이겠지만, 저 같은 노인네 뒷방 개발자들에게는 거의 관심이 없는 주제입니다. "이제 와서 성장해봐야 얼마나 하겠어", "성장한다 한들 얼마나 더 개발자로 일하겠어" 같은 생각들이 더 강한 것일 수도 있고, 그냥 묵묵히 잘하다 보면 성장하는 거지, 성장을 목표로 용쓴다고 달라질 게 별로 없다는 걸 알기 때문이기도 하겠습니다. 초등학생 어린이들은 빨리 어른이 되고 싶다지만, 막상 어른 된 입장에서야 그 생각이 별로 안 들잖아요? 정작 아무 걱정 없이 신나게 노는 아이들이 부러울 따름입니다. 정작 그 아이들은 나름의 심각한 고민들이 많이 있고요. ㅎㅎ
암튼, 결국 근로소득자 입장에서는, 내 지식 노동을 제공하고, 그 대가를 월급으로 받는 것이 핵심이겠습니다. 욕심을 더 부린다면, 그 지식 노동을 생산하는 과정에서, 월급 외에 다른 부산물들이 나나 회사에 더 발생하면 좋은 거죠. 예를 들면, 내 지식 노동의 품질이 더 올라가서, 잠재적으로 연봉이 오른다거나, 더 높은 급여의 회사로 이직이 쉬워진다거나 하는 등의 부산물요.
뒷방 노인네답게, 오로지 "돈돈돈"을 적게 되었는데, 그렇다고, 월급만으로 기준을 최소화해버리면, 내 장기적인 커리어가 망가진다거나, 과도한 정신적 육체적 스트레스로 건강을 해친다거나 하는 부작용이 발생할 수도 있으니, 나름의 적절한 균형점을 찾아야 하겠습니다. 그 균형점이 정말 중요한 것 같아요. 너무 돈만 따져도 안되고, 그렇다고 너무 이상적인 목표에 대해 과도한 욕심을 부려도, 부작용이 클 테니까요.
이런 마인드가 어떤가 생각해봤습니다. 이러니 저리니 해도 월급날 월급은 잘 들어왔고, 난 그 이상의 추가적인 부가 가치를 나에게나 회사에 만들어 냈으면 정말 잘한 거라고요. 반드시 그래야 하는 것은 아니지만, 그게 가능하다면 바람직한 옵션 정도로 여겨보면, 적어도 일단 마음은 편하지 않나 싶습니다.
어떻게 생각하시나요? 지나치게 소박한 목표일까요? 한편, 뭐 그 모든 욕심이나 이상을 한 방에 날려 보내는 현실은, "왜 내 월급은 왜 텅장을 스쳐가고 늘 부족한가"라는 점이 문제겠습니다. 욕심에 비해 늘 부족하지만, 그래도 입금된 월급에 감사하며 마구 적어봤습니다. 이제 뭐 욕심을 줄여야죠. ㅋ
작성일: 2022년 8월 25일
개발자 직급 체계, 그리고 시니어 개발자란?
나보고 시니어 개발자라고?
한 7년 차쯤 되었을 때, 처음 시니어 개발자라고 불린 것 같습니다. 그때는 "시니어 개발자"라는 호칭 자체가 생소했고, 심지어 조금 불쾌하기까지 했어요. 나이도 들고 경력도 좀 되었는데, 마땅히 공식적인 직함 같은 게 없는 상황에, 애써 우대해 불러주고 싶을 때 쓰는 호칭 정도로 느껴졌습니다.
게다가 제가 생각하는 시니어 개발자는 백발머리 성성한 그런 이미지를 떠올렸는데, 아직 30대 초반 청년(?)이었던 저한테 시니어라니?! 당시 제 주변 동료들은 팀장이 된다거나 승진을 한다거나 하는데, 저만 아직 말단 개발자니까, '뭔가 문제시되는 게 아닌가'하는 자격지심 같은 마음이 발동했나 봅니다. 삐딱하게 말이죠.
이젠 뭘로 보나, 시니어 확정
그런데 요새는 왠지 시니어 개발자의 대우가 꽤 좋은 느낌입니다. 채용 시장에서는 물론이고, 개발자 커뮤니티에서도 "시니어 개발자"라는 부류의 사람들을 인정해주는 분위기랄까요? 이미지 자체가 좋아지니, 시니어라 불리는 것에 대해서 느꼈던 거부감이 호감으로 바뀔 지경입니다.
어쨌건, 이제 누가 저보고 "시니어 개발자"라고 말해도, 저 스스로도 어색하지 않은 상황이 갖춰진 것 같습니다. 백발성성까지는 아니더라도, 흰머리도 많아진 건 확실하고요. 췟!
시니어 개발자의 기준
주변에 "시니어 개발자를 판단하는 기준이 무어냐?"라고 물어보면, 대략 주관적으로는 판단이 가능한 것 같습니다만, 경계를 확실히 가르는 객관적 기준이 있는 것 같지는 않습니다. 각자 생각하는 기준이 다를 수 있기에, 회색 영역이 꽤 넓게 자리 잡는 것 같습니다.
한편, 회사들마다 개발자 공개/비공개 레벨 제도가 있다거나, 아예 직급이나 직함이 그 역할을 대신하는 경우도 있는 것 같습니다. 예를 들어, L1부터 L7까지 있는데, 대략 L4부터 시니어라고 부른다거나 하는 식인 거죠.
아니면, 아예 더 주관적으로, "주변 개발자들에게 일을 시킬 수 있는 영향력이 있으면 시니어"라고 한다거나, 아니면 "본인 밥값을 충분히 하고 주변 개발자도 도와주면 시니어"라고 한다는 의견도 들었습니다.
이 주니어/시니어 개발자라는 기준이, 마치, 청년과 장년의 기준이 무어냐와 비슷한 느낌으로 모호한 것 같다고 생각하고 있습니다.
경험한 회사의 위계들
첫직장 -- 사원, 대리, 과장, 차장, 부장, 임원...
오래전 처음 다녔던 회사에서는 전통적인 직급 제도가 있었습니다. 사원은 그냥 누구누구'씨'라는 호칭으로 불렀고, 대리부터 직급과 '님'자를 붙여서 불렀습니다. 그러니까 저보고는 "김대현씨"라고 불렀는데, 이게 뭐, 한국어 문법적으로 따지자면 존댓말이자만, 사실상 하대죠. 그러다 대리가 되면, 윗사람은 '김대현 대리'라고 부르고, 사원들은 '김대현 대리님'이라고 부릅니다.
동일 직급 내에서는 연봉 차이가 거의 없고, 다음 직급으로 승진을 하면 연봉 인상 폭이 좀 티가 나는 점이 인상적입니다. 사실 이런 회사에서는 주니어/시니어의 구분이 의미가 없고, 그냥 직급 자체가 위계를 드러냅니다.
여기서 직급제는, 거의 호봉에 따라서, 3년 근속하고 나면, 내부 승진 심사를 거쳐, 다음 직급이 되는데, 3년 보다 먼저 되면, 대단히 이례적으로 우수한 경우인 거고, 그보다 늦어지면, 뭔가 안 좋은 평가를 받고 있는 거라, 보통의 경우에는 연차에 맞게 거의 정해진 직급으로 이동했던 것 같습니다.
여기서는, 대략 대리에서 과장될까 말까 한 즈음이 '시니어 개발자'로 부를 수 있는 영역이 아니었을까 돌이켜봅니다.
Daum -- 대표이사도 그냥 '님'일 뿐
Daum은 제 입사 당시 젊은 인터넷 기업으로, 서로 호칭을 누구누구'님'이라고 직급 없이 불렀습니다. 그러니까 당시 이재웅 대표이사님 시절인데, 막 입사한 신입사원도, 대표이사를 부를 때, "재웅님"이라고 부르는 거지요. (뭐, 다행인 점은, 대부분 부를 일이 없습니다). 지금이야 IT 업계에서 님 문화나 영어 호칭 문화가 꽤 일반적인 것 같습니다만, 당시에는 나름 파격이었죠.
호칭 자체는 '님'으로 통일하긴 했는데, 인트라넷 프로필이나, 사내 메신저에서 대화할 때에 이름 옆에 직함을 붙여 표기합니다. 팀장이라거나, 본부장이라거나 유닛장이라거나 하는 식으로요.
그래도 사내에서 온/오프라인으로 서로 부를 때는 '님'자로 끝입니다. 제가 팀장이라고 하더라도, 저희 팀원들은 저를 '대현님'이라고 부릅니다. 타이틀 중에 뭐 '개발리더'라는 요망한 것도 해보았는데, 뭐 별 차이점은 없었습니다.
여담으로, 다음에서 오래 근무를 하다 보니, 보통 회사 명함에 있는 흔한 직급이 없어서, 어색한 경우도 있었습니다. 예를 들면, 친척 어르신들은, "아니 왜 10년이나 다녔는데 아직도 사원이냐? 우리 대현이 승진을 못해서 어떻게 하냐?" 이런 걱정을 해주시는 거죠. "저희 회사는 직급 제도가 없이 다 님으로 부릅니다"라고 말씀드리면, "회사가 무슨 동호회냐? 님으로 부르게?"라고 말씀하시거나, 아니면 '승진 못한 게 민망해서 둘러대나 보다'라고 생각하시는 경우도 있었을 것 같습니다.
사내에서는 님 문화로 충분한데, 대외적으로는 직함이라도 있는 것이 대우가 달라지는 체감이 들기도 합니다. 하다못해 은행 대출을 받을 때에도, 팀장 직함을 하나 달고 있으면, 한도가 더 나오는 식인 거죠.
제가 다니던 시절의 다음에서 개발팀장들은 실무 개발은 거의 하지 않았기 때문에, (팀장 == 시니어 개발자)라고 부르기에는 연결이 좀 어렵기는 합니다. 개발자 출신 시니어인 것은 맞지만, 이제는 개발자라고 부르기 어려운 업무를 주로 했습니다.
다음 카카오 -- 영어 이름을 지으라고?
Daum에서 퇴사할 즈음, 카카오와 합병되었습니다. 실제야 어쨌든, 대외적으로는 다음이 카카오를 인수한 모양새였기 때문에, 회사 이름에도 처음에 "다음"이 붙어있기는 했습니다만, 호칭제도는 본 카카오에서 쓰던 대로 영어 이름을 쓰기로 합니다. 카카오에서는 님 호칭으로는 부족하고, 아예 영어식으로 해야 더 수평적인 문화가 장려된다고 여겼나 봅니다.
지금은 어떤지 모르겠으나, 당시 카카오는, 팀장이나 파트장 등이 실무 개발을 꽤 많이 했다고 들었기 때문에, 여기서부터는 대략 타이틀 있는 사람이 시니어 개발자라고 여기면 될 것 같습니다. 물론, 타이틀 없는 사람 중에서도 시니어 개발자로 부를 만한 사람도 많이 있었겠죠.
NHN -- 호오라, 직급 제도가 있네?
NHN의 경우에는, 의외로 직급 제도가 있었습니다. 사원, 선임, 책임, 수석, 이사 등으로요. 용어의 차이만 있을 뿐, 대략 사원-대리-과장-부장 트리와 비슷한 것 같습니다. 저는 수석으로 근무를 했는데, 이게 거기서는 나름 높은 직급이라 특혜와 대우 같은 게 적잖이 있었습니다.
그래도 NHN은, 경력 연차를 기반으로 하기는 하지만, 능력 평가와 업적 평가를 통해, 연차와 딱 매칭시키지는 않는, 나름 유연한 평가를 했던 점이 인상적이었습니다. 승진 심사위원회 같은 걸 열어서, 추천 대상자의 업적을 여러 상위자가 모여서 평가를 합니다. 심지어 대상자의 최근 몇 년 간 산출 결과 문서와, 사내 깃헙 저장소 소스 코드 커밋 내역까지 다 보고 평가를 합니다.
이 과정은, 경력 많은 상위 직급자들 여럿이 모여 어느 정도 객관성을 부여한 합의를 바탕으로 개발적인 성과와 능력을 평가한 기준이 반영되는 거라, 사내에서 책임부터는 '시니어 개발자'다라고 여겨도 될 것 같습니다.
어찌 보면, 이렇게 팀장 같은 직함보다는 이런 승진 직급체계가, 시니어 개발자를 구분할 수 있는 기준에 가까울 것 같다는 생각을 해봤습니다.
LINE+ -- 다시 복귀한 '님'문화
LINE+도, Daum처럼 님 호칭을 씁니다. 저야, Daum에서 경험했기 때문에 익숙했죠. 팀장은 Lead라고 부르고, 차상위 조직장, 그러니까 2차 조직장도 Lead라고 부르고 있는데요, 아마 네이버도 마찬가지인 것 같습니다. "책임리더"라는 타이틀도 있는데, 아마 꽤 높은 타이틀인가 봅니다. 어쨌건 다음과 마찬가지로, 내부에서 서로 부를 때는 타이틀 빼고, 그냥 님이라고 부릅니다.
입사 당시 나머지는 다 님이라 부르고, 일본에 자주 오가는, 대표이사님만 "신상"이라고 일본식 호칭으로 부르더라고요. 라인 본사는 일본에 있는데, 일본에서, 직급을 빼고 누구누구"씨"라고 부르는 걸 파격적으로 장려한 모양입니다. "-상"이라는 게, 우리로 치면 정확히 "-씨"랑 매칭되는 건데, 사장님을 "-씨"라고 부른 거죠, "신씨"라고. 일본에서는 공식적인 호칭에서는 이름이 아니라, 성을 부릅니다.
암튼, 그러다가, 공개적으로 드러나지 않는, 내부적인 개발자 등급 제도를 만든다던데, 어떻게 진행됐는지는 모르겠습니다. 아마 미국 FAANG 같은 회사에서 한다는 개발자 레벨 제도를 도입하려는 것 같습니다.
도입하려는 레벨 제도는, 레벨마다 역할과 책임, 기대사항과 만족해야 할 기준들이 객관적이고 명확하기에, 레벨에 따라 시니어 개발자의 기준을 매핑할 수 있을 것 같습니다. 저 퇴사할 때까지는 도입되지 않았기 때문에 어떻게 진행됐는지는 잘 모르겠습니다.
근데, 사실 듣기에 개발자 레벨이라는 게, 전통적인 직급 제도와 뭐가 다른지 모르겠어요. 그냥 대리, 선임, 책임 등에게, 구체적인 기대 사항만 능력과 성과 중심으로 적시해도 되는 게 아닌가, 왜 굳이 Level이고 숫자로 해야 하나 하는 꼰대적 의문이 들기는 했습니다.
암튼, 능력과 성과를 객관적으로 평가하려는 시도는 응원하는 마음입니다. 단지 나이나 경력 기간만으로 평가한다거나, 아니면 조직장의 주관적 감을 위주로 평가하는 건 문제가 있다고 봅니다. (요새 어디 그런 조직이 있겠나 싶습니다만...)
그래서, 시니어 개발자의 기준은?
사실 "시니어 개발자"에 대해 명시적으로 합의된 기준이 있지는 않은 것 같습니다.
(1) 경력 기준으로 보자면, 대략 5년 차 넘어가면 주니어라고 부르면 실례가 될 것 같고, 그렇다고 시니어라고 부르기에는 애매할 수 있는 영역인 것 같습니다. 한 7년 차 넘어가면 대충 시니어라고 볼 수 있을 것 같기도 합니다.
(2) 특정 회사에서, 나름의 직급이나 레벨 체계를 경험했다면, 대충 시니어 개발자 기준으로 연결지어도 될 것 같고, 이게 그나마 객관적인 기준이 될 것 같습니다.
(3) 경험한 역할로 보자면, 작은 파트나 팀을 대표로 이끌어 개발을 하는 역할이라면 시니어라고 봐도 될 것 같습니다.
아쉬운 마무리
한참을 고민해봐도 마땅한 결론이 쉽게 나는 것 같지는 않습니다. 사실 어쩌면, 시니어 개발자의 기준이 그렇게까지 중요하지는 않기 때문에, 대충 넘어가도 될 것을, 쓸데없이 많은 고민을 했던 건지도 모르겠습니다.
암튼, 제가 다녔던 회사들의 직급과 호칭 체계는 그랬구나 정도로 참고하시면 재밌지 않을까 합니다.
감사합니다.
작성일: 2022년 7월 22일
마이크로 서비스에 Amazon SQS 메시지 큐 활용하기
Amazon SQS란?
Amazon Simple Queue Service(SQS)는 마이크로 서비스, 분산 시스템 및 서버리스 애플리케이션을 쉽게 분리하고 확장할 수 있도록 지원하는 완전관리형 메시지 대기열 서비스입니다. SQS는 메시지 중심 미들웨어를 관리하고 운영하는 데 따른 복잡성과 오버헤드를 없애고 개발자가 차별화 작업에 집중할 수 있도록 지원합니다. SQS를 사용하면 메시지 손실 위험을 감수하거나 다른 서비스를 가동할 필요 없이 소프트웨어 구성 요소 간에 모든 볼륨의 메시지를 전송, 저장 및 수신할 수 있습니다. AWS 관리 콘솔, 명령줄 인터페이스 또는 원하는 SDK, 3가지 간단한 명령을 사용하여 몇 분 만에 SQS를 시작할 수 있습니다.
공식 홈(https://aws.amazon.com/ko/sqs)에 있는 설명입니다. 말이 조금 어렵게 느껴지지만, 정확하게 적혀 있습니다. 이하, 친절한 설명 덧붙여보겠습니다.
메시지 큐 -- MQ
Amazon SQS는 AWS에서 운영해주는 메시지 큐 서비스입니다. 메시지 큐 서비스(또는 메시지 브로커)는, 소프트웨어 시스템 사이에 메시지를 주고받을 수 있는 믿을만한 우체국 시스템이라고 볼 수 있습니다.
핸드폰 통화 연결과, 카카오톡 메시지 연결의 차이로 비유해봐도 될 것 같습니다. 핸드폰 통화 연결은, 즉각적인 대화를 할 수 있습니다만, 당연히도, 통화 당사자 두 명이 둘 다 깨어있고 대화에 집중해야 합니다. (대화에 집중 안 하는 상대도 많다는 점은 논외로 합시다) 한 명이라도 잠든 상태라면 통화 연결이 되지 않을 테고, 대화 진행이 되지 않겠죠.
카카오톡 메시지의 경우에는, 한 명이 운전 중이거나 하는 이유로 잠시 연결이 되지 않더라도, 메시지를 보낸 사람이 메시지를 보내고 다른 일을 하고 있을 수 있고, 받은 사람은 운전을 다 하고 나서, 메시지를 확인한 다음 응답할 수 있습니다.
마이크로 서비스 사이에 메시지 전달을 이어주는 카카오톡이 메시지 큐라고 보면 이해하기 쉬울 것 같습니다. 메시지 큐는 일반적으로 장애에 대한 내성이 (대단히) 높고, 메시지를 안전하게 저장해서 유실되지 않게 보장해 주곤 합니다. 일단 성공적으로 메시지를 큐에 넣었다면, (거의) 반드시 수신자에게 전달된다고 믿을 수 있습니다.
마이크로 서비스끼리 직접 통신
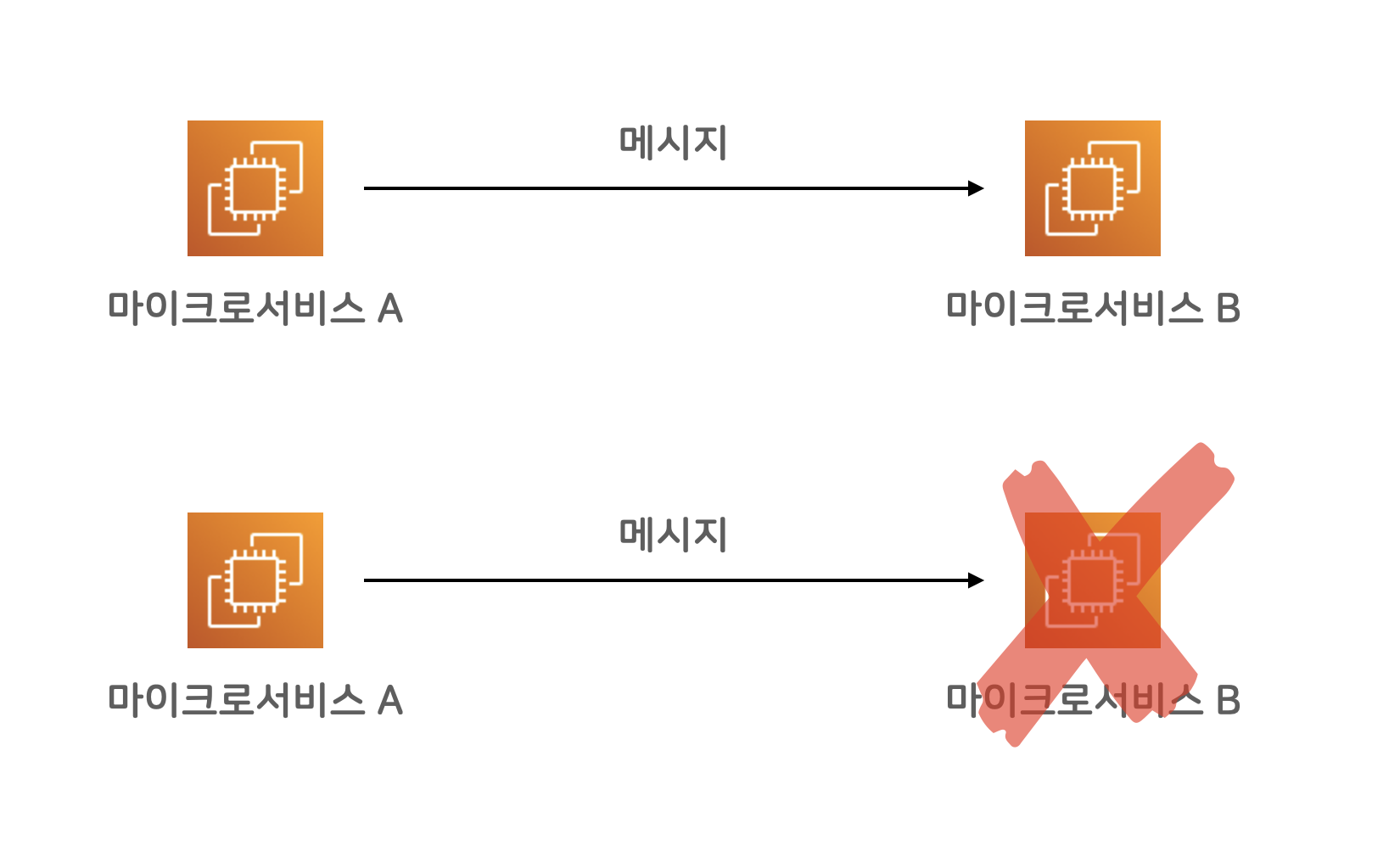
백엔드 마이크로 서비스 A와 B가 통신을 해야 하는 상황에, 보통의 네트워크 통신을 한다면, 즉각적으로 결과를 확인해가며 동기식(synchronous)으로 통신할 수 있습니다만, 대신 A나 B 둘 중 하나만 문제 상황을 만나더라도 전체 시스템이 실패하는 문제가 있습니다.
위 그림에서 보자면, 서비스 B에 장애가 발생하면, 해당 메시지를 주고받아야 했던 상황 전체가, 시스템 차원에서 실패한 꼴이 됩니다. 서비스 A는 문제없이 정상이었는데도 말이죠. A 입장에서는 억울한 상황입니다.
메시지 큐를 활용한 간접 통신
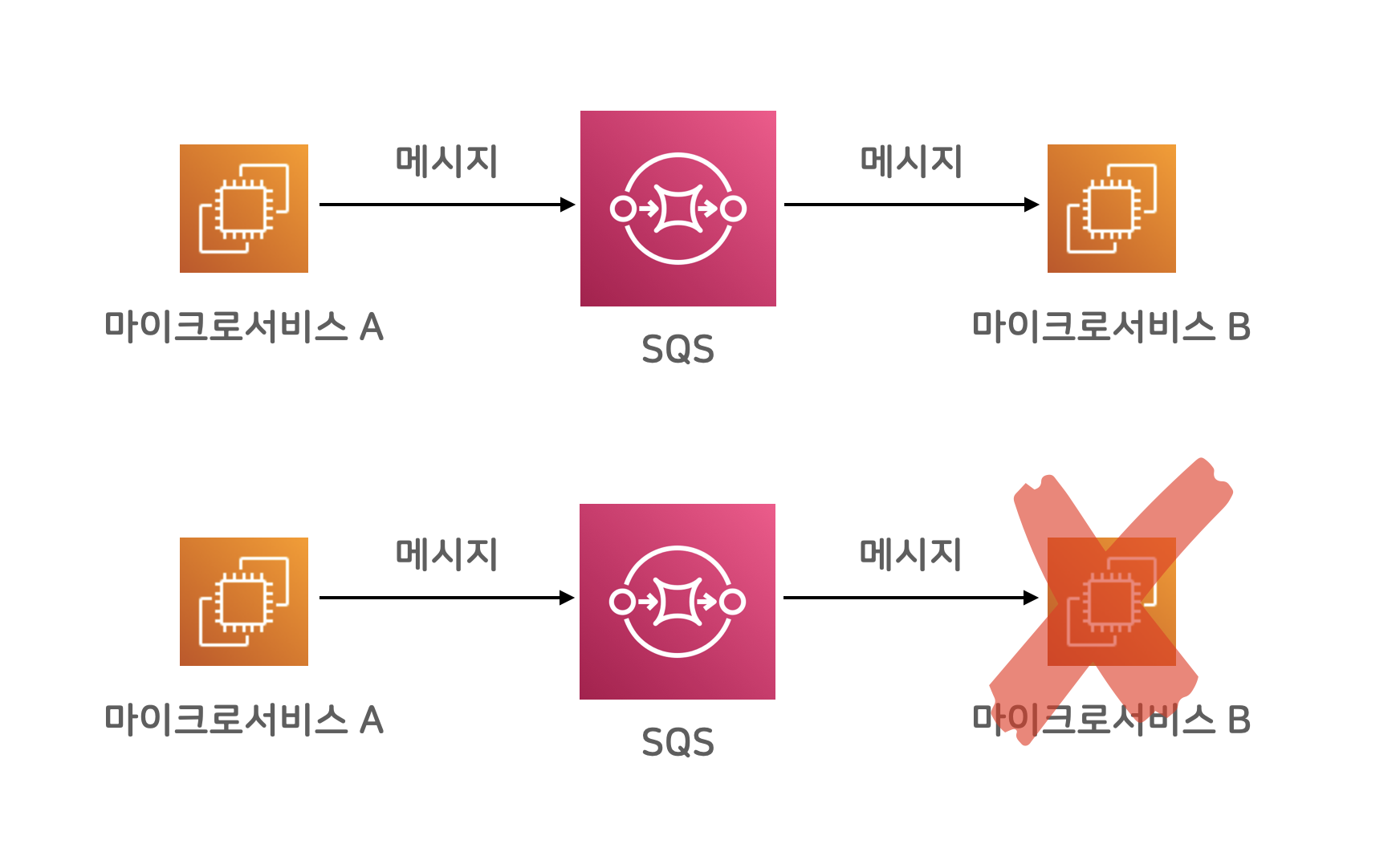
마이크로 서비스 사이 중간에 메시지 큐 서비스를 활용해 통신하면, 메시지 송수신 채널을 유연하게 연결할 수 있습니다. 중간에 메시지 브로커가 안전하고 유연한 버퍼 역할을 해주어서, 메시지를 발송하는 쪽에서는 메시지 수신부가 정상적인지 아닌지 큰 걱정 없이 메시지를 보내고 다른 일을 할 수 있습니다.
마이크로 서비스 B에서 일시적인 문제가 발생했다고 하더라도, 마이크로 서비스 A에서는 정상적으로 메시지를 브로커에 보낼 수 있고, B입장에서는, 다시 정상 작동하는 시점에 메시지를 가져올 수 있습니다. 잠깐의 장애 상황에 대해서 대응할 수 있는 여력이 생긴 거죠.
참고로, 메시지 브로커 서비스는, 다중화 구성을 기본으로 장애 걱정 없이 믿을 만한 시스템으로 구축합니다. 브로커 시스템 일부에 장애가 발생하더라도, 브로커 시스템 전체로 보자면 정상 작동하도록 믿을 수 있는 높은 신뢰도를 바탕으로 운영됩니다. 각자 갖고 있는 스마트폰이 물에 빠지거나 문제가 생길지언정, 카카오톡 서버가 메시지를 유실했다고 생각하기 쉽지 않은 것처럼요.
메시지를 보내는 쪽을 프로듀서(producer)라고 부르고, 받아서 사용하는 쪽을 컨슈머(consumer)라고 부릅니다.
Amazon SQS

메시지 큐 시스템을 자체 인프라에 운영하던 시절에는 오픈 소스 프로젝트로 RabbitMQ가 널리 활용됐었는데요, 클라우드 환경으로 넘어가고, 게다가 AWS에서 책임지고 운영해주는 SQS 같은 브로커 시스템이 등장하면서, 훨씬 더 편리해진 것 같습니다. AWS에서 책임지고 믿을만하게 운영해주기 때문에, 우리는 브로커 운영 부담은 전혀 없이, 각자 개발하는 시스템에서 메시지만 보내고 받아도 되게 된 거죠.
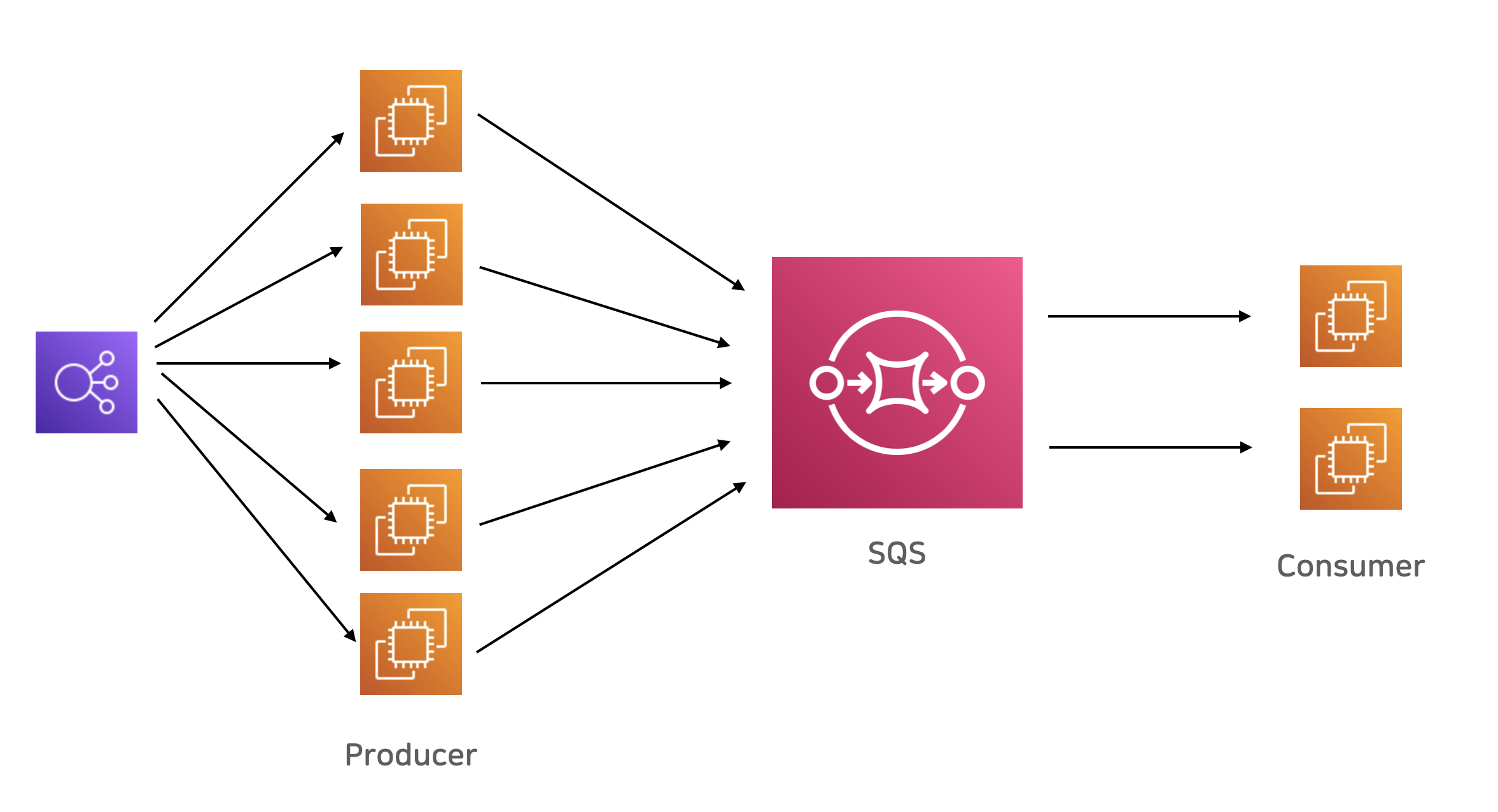
SQS 시스템은 확장성이 매우 뛰어난 브로커 역할을 합니다. 예를 들어, 고객의 요청을 받은 ELB 로드밸런서가, 웹 서비스들로 부하를 분산시켜주고, 각각의 웹 서비스 인스턴스들이 각자 맘 편히 SQS 큐에 메시지를 쌓고, 뒷 단에서 메시지를 처리하는 마이크로 서비스가 묵묵히 자기 일을 하는 식으로 시스템을 구성 할 수 있습니다. DB값을 바꾸는 일처럼, 당장 즉각적인 처리를 반드시 해야 하는 일만 앞단에서 처리하고, 이어서 관련한 시간이 오래 걸리는 일들을 분리해서, 큐 뒷단에서 처리할 수 있겠습니다.
Amazon SQS의 상세 특징
SQS가 메시지 브로커 시스템을 본격 활용하기에 앞서, 구체적인 특징들을 미리 살펴보겠습니다.
기본 특징
- 각 메시지는 최대 256KB 크기입니다. S3에 메시지 본문을 담는 방식을 추가로 지원하기 때문에, 제한 없이 쓸 수도 있습니다.
- 큐에 저장되는 메시지 건 수의 제한은 없습니다.
- 다만 각각의 메시지는 최대 14일간 유지됩니다. 14일 이내에 메시지를 처리(consume) 해야 합니다.
두 가지 큐 종류 -- 표준대기열 vs. FIFO 대기열
보통의 메시지 큐 시스템은, 기본적으로 최소 한번 전송(at least once delivery)을 약속합니다. 혹시 문제가 생기더라도, 최소한 한 번 이상 메시지를 전송해준다는 약속인데요, 그 말은, 같은 메시지가 두 번 이상 수신될 수도 있다는 뜻입니다. 여러 번 수신될 수도 있긴 해도, 어쨌건 유실되지는 않는다는 약속을 지킵니다. 표준대기열은, 이 "최소 한번 전송" 약속을 해주는 큐 시스템이고, FIFO 대기열을 선택하면, 정확히 한번(exactly once) 전송을 약속해 줍니다. 최소 한번 전송 방식에서, 중복 여부를 브로커가 확인해줘서 두 번째 중복 메시지부터는 버려주는 시스템인 셈입니다.
- At least once -- 최소 한 번 이상 메시지 전송을 약속
- Exactly once -- 정확히 딱 한 번 메시지 전송되는 것을 약속 (중복 메시지 제거해줌)
언뜻 보면, 고민할 필요 없이 FIFO 대기열이 좋은 것 같습니다만, 세상에 공짜는 없겠죠? FIFO 대기열 시스템은, 표준 대기열 시스템에 비해서 확장성이 떨어지고, 비용이 약간 비쌉니다. 둘 다 아주 저렴한 수준이어서 비용은 문제가 되지 않을 것 같습니다만, 확장성에 문제가 드러날 수도 있겠습니다.
표준 대기열 시스템은, 사실상 무한대의 처리량을 지원하고, FIFO 시스템은 초당 최대 300건의 메시지 API를 처리할 수 있습니다. 한 번의 API에 최대 10개 메시지를 한 번에 배치 처리할 수 있기 때문에, 매초 최대 3천 건 메시지를 처리할 수 있는 제한이 있는 셈입니다. 꽤 높은 처리량이기 때문에, 대부분의 소규모 시스템에서는 충분하겠습니다만, 규모가 커진다면, 이 제한이 문제가 될 수도 있겠습니다. 그리고, FIFO 시스템은, 메시지 전달 순서도 보장됩니다. 먼저 보낸 메시지가 먼저 수신됩니다. 물론, 수신부(consumer)가 하나여야 의미 있는 얘기가 되겠지만 말이죠.
기능 표준대기열 FIFO 대기열
메시지 보장 최소 한번 (중복 수신 가능) 정확히 한번 처리량 사실상 무제한 최대 3,000메시지/초 비용 약 $0.4/백만건 약 $0.5/백만건 순서보장 순서가 바뀔 수 있다 먼저 송신한 메시지가 먼저 수신된다
메시지 생명주기 -- lifecycle
- 메시지 송신부(producer)가 SQS에 메시지 A를 보냅니다.
- SQS는 메시지A를 사본을 만들어 여러 곳에 안전하게 보관합니다. (유실 방지)
- 수신부(consumer)가 SQS에서 메시지 A를 처리하고자 가져갑니다. (inflight 상태)
- SQS입장에서 수신부가 메시지A를 가져갔기 때문에, 큐에 메시지가 남아있기는 하지만, 다른 컨슈머가 메시지 A를 (또) 가져가지 않도록 일정시간동안(visibility timeout) 수신요청에 드러나지 않습니다.
- 수신부(consumer)가 메시지를 정상 처리 완료했다면, 직접 SQS에 메시지A를 삭제하도록 요청합니다. (완료)
- 만약 어떤 이유로 수신부(consumer)가 메시지를 삭제하지 않는다면, 일정 시간이 지나면, 메시지 A가 다시 수신 요청에 드러납니다. (재처리 가능)
- visibility timeout -- 기본 30초. 0초에서 12시간 사이 설정 가능. 기본은 큐에 설정. 메시지 개별 설정도 가능.
SQS Java 예제
AWS SDK 예제 깃헙에, SQS 관련 예제도 잘 나와있습니다. 그중 일부 예제를 가져와 정리했습니다.
https://github.com/awsdocs/aws-doc-sdk-examples/tree/main/javav2/example_code/sqs
Gradle 의존성 설정
dependencies {
// ...다른 의존성 설정...
implementation platform('software.amazon.awssdk:bom:2.15.0')
implementation 'software.amazon.awssdk:sqs'
}
AWS Java SDK 중, SQS 의존성을 추가합니다.
기본 import
import software.amazon.awssdk.auth.credentials.ProfileCredentialsProvider;
import software.amazon.awssdk.regions.Region;
import software.amazon.awssdk.services.sqs.SqsClient;
import software.amazon.awssdk.services.sqs.model.*;
SQS 클라이언트 준비
SqsClient buildClient() {
return SqsClient.builder()
.region(Region.AP_NORTHEAST_2)
.credentialsProvider(ProfileCredentialsProvider.create())
.build();
}
사용하고자 하는 리전을 지정하고, 적절한 자격증명 설정 방식을 선택합니다.
큐 URL 얻기
String getQueueUrl(SqsClient sqsClient, String queueName) {
try {
GetQueueUrlResponse getQueueUrlResponse =
sqsClient.getQueueUrl(GetQueueUrlRequest.builder().queueName(queueName).build());
String queueUrl = getQueueUrlResponse.queueUrl();
return queueUrl;
} catch (SqsException e) {
System.err.println(e.awsErrorDetails().errorMessage());
System.exit(1);
}
return "";
}
AWS 콘솔이나, 별도 작업으로 만들어 둔 SQS 큐 이름을 기준으로, 큐 접근 URL을 구합니다.
큐에 메시지 보내기
void sendMessage(SqsClient sqsClient, String queueUrl, String message) {
sqsClient.sendMessage(SendMessageRequest.builder()
.queueUrl(queueUrl)
.messageBody(message)
.build());
}
메시지 송신 요청 객체를 만들어서, 큐 URL에 전송하는 코드입니다.
메시지 송신 -- produce
void produce() {
SqsClient sqsClient = buildClient();
String queueUrl = getQueueUrl(sqsClient, "testQueue");
sendMessage(sqsClient, queueUrl, "Hello World!");
sqsClient.close();
}
기본 흐름은, SQS클라이언트를 생성하고, 큐 URL을 구한 뒤, 메시지를 보내고, 클라이언트를 닫으면 됩니다.
메시지 수신 -- consume
void consume(SqsClient sqsClient, String queueUrl) {
ReceiveMessageRequest receiveRequest = ReceiveMessageRequest.builder()
.queueUrl(queueUrl)
.waitTimeSeconds(20)
.build();
ReceiveMessageResponse response = sqsClient.receiveMessage(receiveRequest);
List<Message> messages = response.messages();
messages.forEach(m -> System.out.println(m.body()) );
}
메시지 수신(consume)도 비슷합니다만, 여기서는, 최대 폴링(polling)시간으로 20초를 설정했습니다. 메시지 수신할 때, 한 번에 최대 10건의 메시지가 수신될 수 있기 때문에, List<Message> 타입으로 조회했고, 각각의 메시지들에 대해서, 하고 싶은 처리를 한 다음, SQS 큐에서 삭제(delete) 처리를 하도록 합니다.
다른 서비스 참고
Amazon SQS는, produce-consume 방식의 메시지 송수신에 활용할 수 있고, Amazon SNS는 Pub/Sub 방식에 활용할 수 있습니다. Amazon Kinesis의 경우에는 스크리밍 방식으로 메시지를 송수신할 수 있습니다. 그리고, Apache Kafka의 경우에도 AWS에서 관리형 서비스로 제공하고 있으니, 서비스 요구 사항에 따라서 적절한 서비스를 골라 쓰면 되겠습니다.
대부분의 경우에는, SQS와 SNS를 적절히 조립해서 활용하는 형태로 구성할 것 같습니다. 카프카나 키네시스까지 활용할 일은 흔치 않을 것 같습니다.
이상, Amazon SQS 시스템에 대해 알아보았습니다.
참고자료
- Amazon SQS -- https://aws.amazon.com/ko/sqs/
- Amzons SQS JAVA 예제 -- https://github.com/awsdocs/aws-doc-sdk-examples/tree/main/javav2/example_code/sqs
- SQS, SNS 설명 영상 -- https://youtu.be/UesxWuZMZqI
- SQS, SNS, Lambda 설명 영상 -- https://youtu.be/8zysQqxgj0I
date: 2022년 8월 1일
바쁜 자바 개발자를 위한 스칼라 맛보기
강의 소개
스칼라를 사용하면 자바 개발자로 쌓아온 경험을 그대로 살리면서, 훨씬 간결하고 탄탄한 코드를 빠르게 작성할 수 있습니다. 이 강의는 자바 개발자를 대상으로 기존 자바 지식을 발판 삼아, 빠르게 스칼라의 전체적인 모습을 이해할 수 있게끔 구성했습니다. 기존 자바 개발자라면 아주 쉽게 스칼라도 배우실 수 있습니다.
이런 걸 배워요
- 스칼라 입문
- 자바 기초 복습
- 자바에서 작성하던 흔한 코드를 스칼라로 작성하는 방법
- (자바에는 없지만) 스칼라에만 있는 문법 편의 기능들
- 스칼라에서 예외 처리를 하는 특별한 방법들
- 기존 자바 메서드를 스칼라에서 그대로 활용하는 방법
- 함수형 프로그래밍 맛보기 (합성 함수)
자바 개발자라면? 스칼라로 레벨 업!
혹시 스칼라 관심 있으신가요?
- 자바(Java) 환경에서 일하고 있는데, 더 편리한 방법은 없을지 근본적인 고민이 들어요.
- 함수형 프로그래밍에 관심이 있는데, 너무 학문적인 방식 말고 실용적으로 배울 수 없을까요?
- 업무에서 막 스칼라를 쓰게 됐는데, 좀더 체계적으로 스칼라를 공부해야 할 것 같아요.
예제로 뿌수는 코틀린 Kotlin 76제
76개의 예제로 실습하며 공부하는 코틀린 Kotlin 프로그래밍 언어. 당장 내일부터 코틀린으로 개발해야 하는데, 차근히 문법을 공부할 여유가 없나요? 이 강의에서 알려드리는 예제로 빠르게 코틀린의 모든 문법을 알아봅시다.ㄴ
세련된 언어, Kotlin ✔️
Kotlin(코틀린)은 2011년 JetBrains에서 처음 공개한 프로그래밍 언어로, 현재는 안드로이드 앱 개발 표준 언어입니다. Java와 비슷하지만, 훨씬 현대적인 세련된 문법과 기능을 제공합니다. 백엔드 개발 산업 표준인 Spring 프레임워크에서도 기본 지원하고 있으며, 안드로이드 및 백엔드 멀티플랫폼을 지원합니다.
코틀린을 어떻게 써야 할지 고민하셨나요?
- 🧐 코틀린 언어가 좋다는 얘기를 들었는데, 어떤 면이 좋은지 궁금해요.
- 🥲 당장 코틀린 프로젝트에 참여하게 됐는데, 아직 코틀린 경험이 없어요.
- 🫠 코틀린을 쓰고는 있지만, 아직 코틀린다운 코드를 쓰고 있다는 느낌이 들지 않아요.
예제와 함께 바로 실습하고 바로 적용해 보세요! 📌
본 강의는 예제 실습 중심으로 코틀린 프로그래밍 언어를 학습하는 강의입니다. 코틀린 공식 홈페이지 문서 중 하나인 Kotlin by Example 자료를 한국어로 편역해서 제작했습니다. 코틀린 문법을 이해하기 쉬운 76개의 예제를 함께 실습해 봅니다.
우아한 고성능 프로그래밍 언어 Rust 입문 및 활용
누구나 탄탄하고 효율적인 고성능 소프트웨어를 만들 수 있게 해주는 프로그래밍 언어, Rust를 배우는 강의입니다. 로우레벨 프로그래밍을 할 수 있으면서도 하이레벨 언어기능이 풍부하여 이상적입니다.
세계에서 가장 사랑받는 언어, Rust!
러스트(Rust)는 '스택 오버플로(Stack Overflow)'에서 7년 연속 가장 사랑받는 언어 1위로 뽑혔어요. 현재 러스트를 사용하는 개발자는 전 세계적으로 280만 명에 달합니다. 디스코드(Discord), 클라우드플레어(Cloudflare) 등의 기업에서도 러스트를 사용하고 있어요. 세계가 사랑하는 Rust를 만나보세요!
효율적인 소프트웨어 제작, Rust와 함께
본 강의에서는 차세대 고성능 프로그래밍 언어, Rust를 학습합니다. 로우레벨 프로그래밍을 해야 하지만, C/C++나 Go 같은 언어 기능에 한계를 느낀 분들은 로우레벨 프로그래밍을 지원하면서 고수준의 언어 기능이 탑재된 Rust를 활용하면 됩니다! 강의를 통해 백엔드 실무에 활용할 예제를 다뤄보고, 러스트로 최대 성능의 소프트웨어를 안정적으로 만들어 보세요.
2023년 9월, 2년간 1700K를 달렸다
어쩌다 2년 넘게 오래 달리기를 하고 있습니다. 운동을 해야겠다고 다짐해도 여러 핑계를 대며 다음 날로 미루는 판국에, 그 재미없는 달리기를 한다니요, 말도 안 되죠. 처음에는 작심삼일 세 번만 반복해보자 싶었습니다. 뭐 또 내가 이러다 말겠지만, 그래도 해보자는 마음으로. 그런데 언젠가부터는 '아 내가 달리는 사람이구나'라고 떳떳하게 얘기할 수 있게 됐습니다.
처음에는 억지로 운동량을 채우겠다는 심정이었는데, 훗날 알고 보니 이 '달리기'라는 운동이 상당히 재미가 있는 겁니다. 뛰는 사람들 참 대단한 의지다라고 느꼈더랬는데, 사실은 이 분들이 의지로만 하는 게 아니었던 겁니다. 실제로 재밌기 때문에 계속할 수 있는 거였습니다. 달리는 사람들이 날 속인 적은 없지만, 제 스스로 속은 겁니다. 다 대단한 의지와 체력이 있는 사람들인 줄 알았는데, 그 의지가 내가 생각했던 만큼 대단한 의지는 아니었던 거죠.
처음에는 1주일에 두 번 뛰는 걸 목표로 했고, 한 번에 5K를 쉬지 않고 뛸 수 있는 체력을 갖추고 싶었습니다. 평생 오래 달리기라는 종목을 기피했기에, 힘든 건 둘째치고 혹시 무릎이나 발목에 부상을 입으면 어쩌나 하는 걱정에 조심했습니다. 다행히 별다른 부상이 없었고 3개월쯤 지나니 5K를 한 번에 뛸 수 있게 됐습니다.
그러다가, 주변 사람들 분위기에 휩쓸려, 마라톤 대회에 함께 치러지는 10K 달리기도 나가보고, 하프마라톤도 나가봤습니다. 다음 달 트레일러닝 20K 대회도 앞두고 있습니다. 대회를 앞두면 확실한 목표의식이 생겨서, 훈련량을 늘릴 수 있는 동기가 충분해집니다만, 굳이 그렇지 않아도 평소에 늘 습관적으로 잘 뛰고 있기 때문에 큰 차이는 없습니다. 요새는 매주 4~5회 뛰면서 한 달 100K 정도를 뛰고 있고, 연말까지 160K 정도로 늘리려 합니다. 다른 사람이 보기에는 많은 거리일 수도 있고, 적은 거리일 수도 있습니다. 각자 본인의 페이스와 마일리지가 있어서 각자 기준으로 하면 되는 것 같습니다.
그렇게 오래 뛴 것도 아니고, 많이 뛰는 것도 아니고, 잘 뛰는 것도 아니지만, 그래도 이제는 달리는 사람으로서, 달리기가 제 생활에 있어서 적지 않은 부분을 차지하고 있기에, 틈틈이 관련한 생각을 적어보는 것도 재밌을 것 같습니다. 달리기를 추천하는 글들이 될 수도 있겠지만, 어차피 누군가 추천한다고 해서 이걸 재밌게 할 수 있는 거는 아닐 수도 있어서, 그저 이미 뛰는 사람들의 공감을 받을 수 있다면 충분하겠다는 기대입니다.
적어도 저는 누군가를 속이지 않으려 합니다. 달리는 건 그렇게 대단한 의지로 하는 게 아닙니다. 실제로 재미가 있기 때문에 계속할 수 있습니다. 의지로만 하라면 힘들고 지쳐서 오래 지속할 수 없을 거예요. 재미가 없다면, 굳이 할 필요도 없습니다. 다른 재밌는 운동도 많을 테니까요.